Закат эпохи алгоритма MD5?

Хеш-функция — функция, осуществляющая преобразование массива входных данных произвольной длины в выходную битовую строку установленной длины, выполняемое определенным алгоритмом. Преобразование, производимое хеш-функцией, называется хешированием. Результат преобразования называется хешем.
Хеш-функции применяются в следующих случаях:
- При построении ассоциативных массивов.
- При поиске дубликатов в последовательностях наборов данных.
- При построении уникальных идентификаторов для наборов данных.
- При вычислении контрольных сумм от данных для последующего обнаружения в них ошибок, возникающих при хранении и передаче данных.
- При сохранении паролей в системах защиты в виде хеш-кода (для восстановления пароля по хеш-коду требуется функция, являющаяся обратной по отношению к использованной хеш-функции).
- При выработке электронной подписи (на практике часто подписывается не само сообщение, а его хеш-образ).
С точки зрения математики, контрольная сумма является результатом хеш-функции, используемой для вычисления контрольного кода — небольшого количества бит внутри большого блока данных, например, сетевого пакета или блока компьютерного файла, применяемого для обнаружения ошибок при передаче или хранении информации. Значение контрольной суммы добавляется в конец блока данных непосредственно перед началом передачи или записи данных на какой-либо носитель информации. Впоследствии оно проверяется для подтверждения целостности данных. Популярность использования контрольных сумм для проверки целостности данных обусловлена тем, что подобная проверка просто реализуема в двоичном цифровом оборудовании, легко анализируется и хорошо подходит для обнаружения общих ошибок, вызванных наличием шума в каналах передачи данных.
MD5 — алгоритм хеширования, разработанный профессором Рональдом Л. Ривестом из Массачусетского технологического института в 1991 году. Предназначен для создания контрольных сумм или «отпечатков» сообщения произвольной длины и последующей проверки их подлинности. Алгоритм MD5 основан на алгоритме MD4.
Как работает протокол?

Утилита md5sum, предназначенная для хеширования данных заданного файла по алгоритму MD5, возвращает строку. Она состоит из 32 цифр в шестнадцатеричной системе счисления (016f8e458c8f89ef75fa7a78265a0025).
То есть хеш, полученный от функции, работа которой основана на этом алгоритме, выдает строку в 16 байт (128) бит. И эта строка включает в себя 16 шестнадцатеричных чисел. При этом изменение хотя бы одного ее символа приведет к последующему бесповоротному изменению значений всех остальных битов строки.
В данном алгоритме предполагается наличие 5 шагов, а именно:
- Выравнивание потока
- Добавление длины сообщения
- Инициализация буфера
- Вычисление в цикле
- Результат вычислений
На первом шаге “Выравнивание потока” сначала дописывают единичный бит в конец потока, затем необходимое число нулевых бит. Входные данные выравниваются так, чтобы их новый размер был сравним с 448 по модулю 512. Выравнивание происходит, даже если длина уже сравнима с 448.
На втором шаге в оставшиеся 64 бита дописывают 64-битное представление длины данных до выравнивания. Сначала записывают младшие 4 байта. Если длина превосходит то дописывают только младшие биты. После этого длина потока станет кратной 512. Вычисления будут основываться на представлении этого потока данных в виде массива слов по 512 бит.
На третьем для вычислений используются четыре переменные размером 32 бита и задаются начальные значения в 16-ричном виде. В этих переменных будут храниться результаты промежуточных вычислений.
Во время 4-го шага “Вычисление в цикле” происходит 4 раунда, в которых сохраняются значения, оставшиеся после операций над предыдущими блоками. После всех операций суммируются результаты двух последних циклов. Раундов в MD5 стало 4 вместо 3 в MD4. Добавилась новая константа для того, чтобы свести к минимуму влияние входного сообщения. В каждом раунде на каждом шаге и каждый раз константа разная. Она суммируется с результатом и блоком данных. Результат каждого шага складывается с результатом предыдущего шага. Из-за этого происходит более быстрое изменение результата. Изменился порядок работы с входными словами в раундах 2 и 3.
В итоге на 5-ом шаге мы получим результат вычислений, который находится в буфере это и есть хеш. Если выводить побайтово, начиная с младшего байта первой переменной и закончив старшим байтом последней, то мы получим MD5-хеш.
Уязвимости MD5

Алгоритм MD5 уязвим к некоторым атакам. Например, возможно создание двух сообщений с одинаковой хеш-суммой.
На данный момент существуют несколько видов взлома хешей MD5 — подбора сообщения с заданным хешем:
- Перебор по словарю
- Brute-force
- RainbowCrack
- Коллизия хеш-функции
При этом методы перебора по словарю и brute-force могут использоваться для взлома хеша других хеш-функций (с небольшими изменениями алгоритма). RainbowCrack требует предварительной подготовки радужных таблиц, которые создаются для заранее определённой хеш-функции. Поиск коллизий специфичен для каждого алгоритма. Рассмотрим каждый вид «взлома» по отдельности.
Атаки переборного типа

В криптографии атака полного перебора или исчерпывающий поиск ключей это стратегия, которая теоретически может быть использована против любых зашифрованных данных. Злоумышленник, который не может воспользоваться слабостью в системе шифрования, реализовывает атаку подобного типа. Она включает в себя систематическую проверку всех возможных ключей, пока не будет найден правильный. В худшем случае для взлома сообщения потребуется задействовать всю вычислительную мощность.
Перебор по словарю — атака на систему защиты, применяющая метод полного перебора предполагаемых паролей, используемых для аутентификации, осуществляемого путём последовательного пересмотра всех слов (паролей в чистом виде) определённого вида и длины из словаря с целью последующего взлома системы и получения доступа к секретной информации.
Как видно из определения, атаки по словарю являются атаками полного перебора. Единственное отличие состоит в том, что данные атаки обычно более эффективны так как становится не нужным перебирать все комбинации символов, чтобы добиться успеха. Злоумышленники используют обширные списки наиболее часто используемых паролей таких как, имена домашних животных, вымышленных персонажей или конкретно характерных слов из словаря – отсюда и название атаки. Однако если пароль действительно уникален (не является комбинацией слов), атака по словарю не сработает. В этом случае использование атаки полного перебора единственный вариант.
Для полного перебора или перебора по словарю можно использовать программы PasswordsPro, MD5BFCPF, John the Ripper. Для перебора по словарю существуют готовые словари.
RainbowCrack

Это ещё один метод взлома хеша. Он основан на генерировании большого количества хешей из набора символов, чтобы по получившейся базе вести поиск заданного хеша.
Радужные таблицы состоят из хеш-цепочек и более эффективны, чем предыдущий упомянутый тип атак, поскольку они оптимизируют требования к хранению, хотя поиск выполняется немного медленнее. Радужные таблицы отличаются от хеш-таблиц тем, что они создаются с использованием как хеш-функций, так и функций редукции.
Цепочки хешей — метод для уменьшения требования к объёму памяти. Главная идея — определение функции редукции R, которая сопоставляет значениям хеша значения из таблицы. Стоит отметить, что R не является обращением хеш-функции.
Радужные таблицы являются развитием идеи таблицы хеш-цепочек. Функции редукции применяются по очереди, перемежаясь с функцией хеширования.
Использование последовательностей функций редукции изменяет способ поиска по таблице. Поскольку хеш может быть найден в любом месте цепочки, необходимо сгенерировать несколько различных цепочек.
Существует множество систем взлома паролей и веб-сайтов, которые используют подобные таблицы. Основная идея данного метода — достижение компромисса между временем поиска по таблице и занимаемой памятью. Конечно, использование радужных таблиц не гарантирует 100% успеха взлома систем паролей. Но чем больше набор символов, используемый для создания радужной таблицы, и чем продолжительнее хеш-цепочки, тем больше будет шансов получить доступ к базе данных исходных паролей.
Коллизии MD5

Коллизия хеш-функции — это получение одинакового значения функции для разных сообщений и идентичного начального буфера. В отличие от коллизий, псевдоколлизии определяются как равные значения хеша для разных значений начального буфера, причём сами сообщения могут совпадать или отличаться. В 1996 году Ганс Доббертин нашёл псевдоколлизии в MD5, используя определённые инициализирующие векторы, отличные от стандартных. Оказалось, что можно для известного сообщения построить второе такое, что оно будет иметь такой же хеш, как и исходное. С точки зрения математики, это означает следующее:
где — начальное значение буфера, а и — различные сообщения.
MD5 был тщательно изучен криптографическим сообществом с момента его первоначального выпуска и до 2004 года демонстрировал лишь незначительные недостатки. Однако летом 2004 года криптографы Ван Сяоюнь и Фэн Дэнго продемонстрировали алгоритм способный генерировать MD5-коллизии с использованием стандартного вектора инициализации.
Позже данный алгоритм был усовершенствован, как следствие время поиска пары сообщений значительно уменьшилось, что позволило находить коллизии с приемлемой вычислительной сложностью. Как оказалось, в MD5 вопрос коллизий не решается.
Безопасное использование MD5
MD5 – до сих пор является одним из самых распространенных способов защитить информацию в сфере прикладных исследований, а также в области разработки веб-приложений. Хеш необходимо обезопасить от всевозможных хакерских атак.
Информационная энтропия

Надежность и сложность пароля в сфере информационных технологий обычно измеряется в терминах теории информации. Чем выше информационная энтропия, тем надежнее пароль и, следовательно, тем труднее его взломать.
Чем длиннее пароль и чем больше набор символов, из которого он получен, тем он надежнее. Правда вместо количества попыток, которые необходимо предпринять для угадывания пароля, принято вычислять логарифм по основанию 2 от этого числа, и полученное значение называется количеством «битов энтропии» в пароле. При увеличении длины пароля на один бит количество возможных паролей удвоится, что сделает задачу атакующего в два раза сложнее. В среднем, атакующий должен будет проверить половину из всех возможных паролей до того, как найдет правильный. В качестве наилучшей практики должно выполняться предварительное требование: приложение настаивает на том, чтобы пользователь использовал надежный пароль в процессе регистрации.
Добавление “соли” к паролю

Одна из наиболее распространенных причин успешных атак заключается в том, что компании не используют добавление соли к исходному паролю. Это значительно облегчает хакерам взлом системы с помощью атак типа радужных таблиц, особенно учитывая тот факт, что многие пользователи используют очень распространенные, простые пароли, имеющие одинаковые хеши.
Сольэто вторичный фрагмент информации, состоящий из строки символов, которые добавляются к открытому тексту (исходному паролю пользователя), а затем хешируется. Соление делает пароли более устойчивыми к атакам типа радужных таблиц, так как подобный пароль будет иметь более высокую информационную энтропию и, следовательно, менее вероятное существование в предварительно вычисленных радужных таблицах. Как правило, соль должна быть не менее 48 бит.
Декодирование кода MD5
Иногда при работе с компьютером или поврежденными базами данных требуется декодировать зашифрованное с помощью MD5 значение хеша.
Удобнее всего использовать специализированные ресурсы, предоставляющие возможность сделать это online:

- md5.web-max.ca данный сервис обладает простым и понятным интерфейсом. Для получения декодированного значения нужно ввести хеш и заполнить поле проверочной капчи;
- md5decrypter.com аналогичный сервис;
- msurf.ru данный ресурс имеет простой русскоязычный интерфейс. Его функционал позволяет не только расшифровывать значения хеш-кодов, но и создавать их.
Если присмотреться к значениям декодинга, то становится понятно, что процесс расшифровки почти не дает результатов. Эти ресурсы представляют собой одну или несколько объединенных между собой баз данных, в которые занесены расшифровки самых простых слов.
При этом данные декодирования хеша MD5 даже такой распространенной части пароля, как «админ», нашлись лишь в одной базе. Поэтому хеши паролей, состоящих из более сложных и длинных комбинаций символов, практически невозможно расшифровать.
Создание хеша MD5 является односторонним процессом. Поэтому не подразумевает обратного декодирования первоначального значения.
Заключение
Как уже отмечалось ранее, основная задача любой функции хеширования сообщений производить образы, которые можно считать относительно случайными. Чтобы считаться криптографически безопасной, хэш-функция должна отвечать двум основным требованиям. Во-первых, злоумышленник не может сгенерировать сообщение, соответствующее определенному хеш-значению. Во-вторых, невозможно создать два сообщения, которые производят одно и то же значение (коллизии в MD5).
К сожалению, выяснилось, что алгоритм MD5 не способен отвечать данным требованиям. IETF (Internet Engineering Task Force) рекомендовала новым проектам протоколов не использовать MD5, так как исследовательские атаки предоставили достаточные основания для исключения использования алгоритма в приложениях, которым требуется устойчивость к различного рода коллизиям.
Хеши MD5 больше не считаются безопасными, и их не рекомендовано использовать для криптографической аутентификации.
78. Контрольные суммы. Md5. Алгоритм md5.
Контро́льная су́мма — некоторое значение, рассчитанное по набору данных путём применения определённого алгоритма и используемое для проверки целостности данных при их передаче или хранении. Так же контрольные суммы могут использоваться для быстрого сравнения двух наборов данных на неэквивалентность: с большой вероятностью различные наборы данных будут иметь неравные контрольные суммы. Это может быть использовано, например, для детектирования компьютерных вирусов. Несмотря на своё название, контрольная сумма не обязательно вычисляется путем суммирования.
MD5 и другие криптографические хеш-функции используются, например, для подтверждения целостности и подлинности передаваемых данных.
Сам алгоритм состоит из 5 шагов.
Шаг 1. Добавление битов.
Исходное сообщение дополняется до длины 512k+448, где k – любое натуральное число. Длина сообщения измеряется в битах. Для этого в конец сообщения (бит под номером N) добавляется бит, равный 1. Вслед за ним биты под номерами N+1, N+2, … заполняются нулями до тех пор, пока длина сообщения не достигнет необходимого. Таким образом, число добавляемых битов – от 1 до 512.
Шаг 2. Добавление длины сообщения.
Считаем длину исходного сообщения в двоичном представлении. Например, если длина составляла 1926 бит, то нам необходимо перевести 1926 в двоичную систему счисления: 11110000110. Полученную длину необходимо представить в 64-битном формате. То есть заполняем старшие биты нулями.
Полученное 64-битовое значение добавляется в конец результата шага 1 как два слова.
После этого размер сообщения станет кратен 512, и оно будет содержать целое количество блоков по 16 слов. Обозначим как M[0..L-1] слова полученного в результате сообщения. L кратно 16.
Шаг 3. Инициализация буфера.
Вводим 4 регистра для хранения промежуточных вычислений: A, B, C, D. Инициализируем их (16ричное представление, сначала идёт младший байт):
Шаг 4. Обработка сообщения блоками по 16 слов.
Определим четыре дополнительных функции. На вход каждой из них подаётся 3 слова, на выходе получаем 1 слово.
F (X,Y,Z) = XY v not (X)Z
G(X,Y,Z) = XZ v not(Z)Y
H(X,Y,Z) = X xor Y xor Z
I(X,Y,Z) = Y xor (X v not(Z))
Определим массив T[1..64], где T[i]=int(2^32*|sin(i)|). Здесь i задано в радианах.
Приступим к обработке исходного сообщения. Как мы помним, его длина кратна 512 и содержит целое количество блоков L по 16 слов: M[0..L-1].
В цикле проходим по массиву M, и каждое слово M[i] (блок) проходит 4 раунда из 16 операторов.
Предварительно сохраним значения, хранимые в регистрах A, B, C, D:
Теперь прогоним текущий блок по следующим раундам.
/*[abcd k s i] a = b + ((a + F(b,c,d) + M[k] + T[i])
[ABCD 0 7 1][DABC 1 12 2][CDAB 2 17 3][BCDA 3 22 4]
[ABCD 4 7 5][DABC 5 12 6][CDAB 6 17 7][BCDA 7 22 8]
[ABCD 8 7 9][DABC 9 12 10][CDAB 10 17 11][BCDA 11 22 12]
[ABCD 12 7 13][DABC 13 12 14][CDAB 14 17 15][BCDA 15 22 16]
/*[abcd k s i] a = b + ((a + G(b,c,d) + M[k] + T[i])
[ABCD 1 5 17][DABC 6 9 18][CDAB 11 14 19][BCDA 0 20 20]
[ABCD 5 5 21][DABC 10 9 22][CDAB 15 14 23][BCDA 4 20 24]
[ABCD 9 5 25][DABC 14 9 26][CDAB 3 14 27][BCDA 8 20 28]
[ABCD 13 5 29][DABC 2 9 30][CDAB 7 14 31][BCDA 12 20 32]
/*[abcd k s i] a = b + ((a + H(b,c,d) + M[k] + T[i])
[ABCD 5 4 33][DABC 8 11 34][CDAB 11 16 35][BCDA 14 23 36]
[ABCD 1 4 37][DABC 4 11 38][CDAB 7 16 39][BCDA 10 23 40]
[ABCD 13 4 41][DABC 0 11 42][CDAB 3 16 43][BCDA 6 23 44]
[ABCD 9 4 45][DABC 12 11 46][CDAB 15 16 47][BCDA 2 23 48]
/*[abcd k s i] a = b + ((a + I(b,c,d) + M[k] + T[i])
[ABCD 0 6 49][DABC 7 10 50][CDAB 14 15 51][BCDA 5 21 52]
[ABCD 12 6 53][DABC 3 10 54][CDAB 10 15 55][BCDA 1 21 56]
[ABCD 8 6 57][DABC 15 10 58][CDAB 6 15 59][BCDA 13 21 60]
[ABCD 4 6 61][DABC 11 10 62][CDAB 2 15 63][BCDA 9 21 64]
После прохода блока через раунды регистры суммируются с результатом работы предыдущего цикла:
Все числа в каждом раунде выбраны для увеличения криптостойкости алгоритма.
Шаг 5. Вывод хеша.
Последовательно выводим регистры A, B, C, D. То есть начинаем вывод с младшего байта A и заканчиваем старшим байтом D. Выведенное значение – хеш MD5
В следующей статье мы рассмотрим криптостойкость алгоритма MD5 и проанализируем возможные способы для его взлома.
Хэш-функция MD5
Хэш-функция предназначена для свертки входного массива любого размера в битовую строку, для MD5 длина выходной строки равна 128 битам. Для чего это нужно? К примеру у вас есть два массива, а вам необходимо быстро сравнить их на равенство, то хэш-функция может сделать это за вас, если у двух массивов хэши разные, то массивы гарантировано разные, а в случае равенства хэшей — массивы скорее всего равны.
Однако чаще всего хэш-функции используются для проверки уникальности пароля, файла, строки и тд. К примеру, скачивая файл из интернета, вы часто видите рядом с ним строку вида b10a8db164e0754105b7a99be72e3fe5 — это и есть хэш, прогнав этот файл через алгоритм MD5 вы получите такую строку, и, если хэши равны, можно с большой вероятностью утверждать что этот файл действительно подлинный (конечно с некоторыми оговорками, о которых расскажу далее).
Конкретнее о MD5
Не буду углубляться в историю создания, об этом можно почитать в википедии, однако отмечу что алгоритм был создан профессором Р. Риверстом в 1991 году на основе алгоритма md4. Описан этот алгоритм в RFC 1321
Алгоритм состоит из пяти шагов:
1)Append Padding Bits
В исходную строку дописывают единичный байт 0х80, а затем дописывают нулевые биты, до тех пор, пока длина сообщения не будет сравнима с 448 по модулю 512. То есть дописываем нули до тех пор, пока длина нового сообщения не будет равна [длина] = (512*N+448),
где N — любое натуральное число, такое, что это выражение будет наиболее близко к длине блока.
2)Append Length
Далее в сообщение дописывается 64-битное представление длины исходного сообщения.
3)Initialize MD Buffer
На этом шаге инициализируется буффер
word A: 01 23 45 67
word B: 89 ab cd ef
word C: fe dc ba 98
word D: 76 54 32 10
Как можно заметить буффер состоит из четырех констант, предназначенный для сбора хэша.
4)Process Message in 16-Word Blocks
На четвертом шаге в первую очередь определяется 4 вспомогательные логические функции, которые преобразуют входные 32-битные слова, в, как ни странно, в 32-битные выходные.
F(X,Y,Z) = XY v not(X) Z
G(X,Y,Z) = XZ v Y not(Z)
H(X,Y,Z) = X xor Y xor Z
I(X,Y,Z) = Y xor (X v not(Z))
Также на этом шаге реализуется так называемый «белый шум» — усиление алгоритма, состоящее 64 элементного массива, содержащего псевдослучайные числа, зависимые от синуса числа i:
T[i]=4,294,967,296*abs(sin(i))
Далее начинается «магия». Копируем каждый 16-битный блок в массив X[16] и производим манипуляции:
AA = A
BB = B
CC = C
DD = D
Затем происходят «чудесные» преобразования-раунды, которых всего будет 4. Каждый раунд состоит из 16 элементарных преобразований, которые в общем виде можно представить в виде [abcd k s i], которое, в свою очередь, можно представить как A = B + ((A + F(B,C,D) + X[k] + T[i]) A, B, C, D — регистры
F(B,C,D) — одна из логических функций
X[k] — k-тый элемент 16-битного блока.
T[i] — i-тый элемент таблицы «белого шума»
Приводить все раунды не имеет смысла, все их можно посмотреть тут
Ну и в конце суммируем результаты вычислений:
A = A + AA
B = B + BB
C = C + CC
D = D + DD
5) Output
Выводя побайтово буффер ABCD начиная с A и заканчивая D получим наш хэш.
Надежность
Существует мнение что взломать хэш MD5 невозможно, однако это неправда, существует множество программ подбирающих исходное слово на основе хэша. Абсолютное большинство из них осуществляет перебор по словарю, однако существуют такие методы как RainbowCrack, он основан на генерировании множества хэшей из набора символов, чтобы по получившейся базе производить поиск хэша.
Также у MD5, как у любой хэш-функции, существует такое понятие как коллизии — это получение одинаковых хэшей для разных исходных строк. В 1996 году Ганс Доббертин нашёл псевдоколлизии в MD5, используя определённый инициализирующий буффер (ABCD). Также в 2004 году китайские исследователи Ван Сяоюнь, Фен Дэнгуо, Лай Сюэцзя и Юй Хунбо объявили об обнаруженной ими уязвимости в алгоритме, позволяющей за небольшое время (1 час на кластере IBM p690) находить коллизии. Однако в 2006 году чешский исследователь Властимил Клима опубликовал алгоритм, позволяющий находить коллизии на обычном компьютере с любым начальным вектором (A,B,C,D) при помощи метода, названного им «туннелирование».
Прилагаю собственный пример реализации функции на C#:
md5.rar
Контрольная сумма: проверка MD5 хэша файла
![]()
Предположим, у вас есть увесистый дистрибутив софта в формате .iso, гигабайт на 5, например, и вы хотите передать его через сеть партнеру. Вы загружаете его на FTP сервер и даете ссылку партнеру, мол «На, скачивай, дружище!». Ваш партнер скачивает его и работает с ним. Думаете этого достаточно? Нет. Сейчас объясним почему.
Зачем сверять контрольную сумму?
Дело в том, что при загрузке файла из сети файл может прилететь к вам побитым. Да –да, вы не ослышались. Любой .iso это так или иначе, набор блоков данных. И при скачивании, а особенно по нестабильному FTP, он может «крашнуться».
И чтобы избежать этого, используется следующий алгоритм передачи файла. Его последовательность такова:
- Владелец файла считает контрольную сумму рабочего файла (по MD5, например);
- Загружает файл на публичное хранилище и передает контрольную сумму получателю файла;
- Получатель файла скачивает файл, считает его контрольную сумму на своей стороне и сверяет ее с оригинальной, которую посчитал владелец файла;
Получатель и Владелец кидают смешные стикеры в Telegram друг другу из стикерпака про лягушку Пепе.
Как работает контрольная — простым языком
Контрольная сумма — результат некой хэш – функции. Запомнили. Далее, что такое хэш – функция? Это функция, которая получает на вход массив данных, «прокручивает» эти данные по определенному алгоритму и дает на выходе битовую строку, длина которой задана заранее.
Не вдаваясь в подробности сложных алгоритмов, так это и работает:
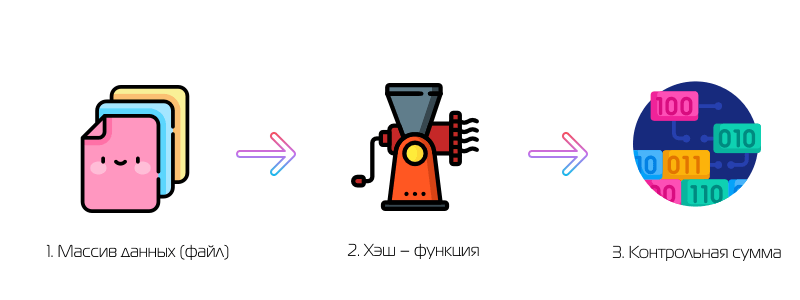
- Массив данных на вход (файл);
- Магия внутри;
- Контрольная сумма на выходе!
Как рассчитать контрольную сумму?
Будем использовать криптографическую функцию MD5. Скачиваем утилиту WinMD5Sum по ссылке: https://sourceforge.net/projects/winmd5sum/. Установите ее и идем дальше.
Итак, вот мой заветный дистрибутив. Лежит в папке:
Запускаем WinMD5Sum:
Тут все предельно просто. Просто в поле File Name выбираем наш дистрибутив и нажимаем кнопку Calculate.
Зачастую, как только вы выберите файл в поле File Name через кнопку поиску (три точки), то подсчет хэша начнется без нажатия на кнопку Calculate.
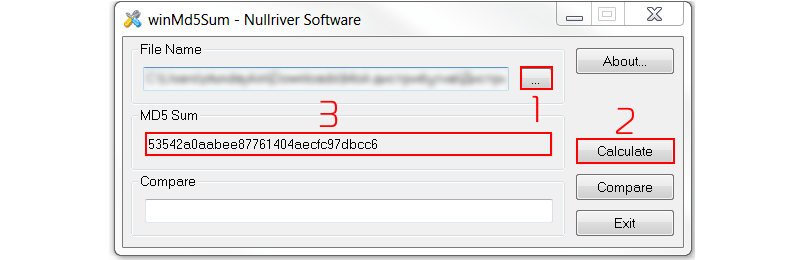
Огонь. Копируйте значение из поля MD5 Sum и сохраняйте себе отдельно. Теперь, по легенде, мы берем этот файл и отправляем другу/партнеру/коллеге. Выкладываем файл на FTP, а контрольную сумму передаем ему отдельно – по смс, емаил, в чате. Далее, давайте рассмотрим процесс с точки зрения получателя файла.
Как сверить контрольную сумму?
Мы получили файл и его контрольную сумму. Как ее проверить? Все так же, как и при расчете контрольной суммы! Сначала считаем контрольную сумму скачанного файла:
С одним лишь отличием. Теперь мы берем контрольную сумму которая была посчитана ранее, вставляем ее в поле Compare и нажимаем кнопку Compare:
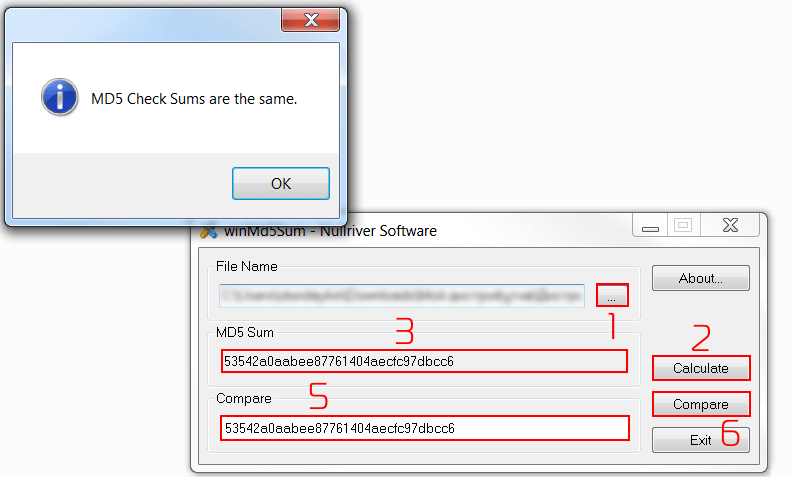
Вот и все. Наша контрольная сумма совпала, а это значит, что файл во время загрузки поврежден не был. Иначе, мы бы получили вот такое значение: