Русские Блоги
Сравнение Hive, Spark SQL и Impala
Три распределенных механизма запросов SQL Hive, Spark SQL и Impala — все это решения SQL-on-Hadoop, но у каждого есть свои особенности. Я уже обсуждал Hive и Impala. В этом разделе сначала представлен SparkSQL, а затем сравниваются сходства и различия между этими тремя продуктами с точки зрения функций, архитектуры и сценариев использования. Наконец, прикрепите три продукта, представленные Cloudera и SAS соответственно. Отчет о сравнении производительности продукта.
Введение в Spark SQL
Spark SQL — это программный модуль Spark, обрабатывающий структурированные данные. В отличие от других базовых API-интерфейсов Spark RDD, интерфейс, предоставляемый Spark SQL, содержит больше структурной информации о данных и расчетах, и Spark SQL будет использовать эту дополнительную информацию для выполнения оптимизации. Вы можете взаимодействовать со Spark SQL через SQL и API наборов данных, но независимо от того, какой язык или API используется для запроса к Spark SQL, внутри используется один и тот же механизм выполнения. Это единообразие позволяет разработчикам легко переключаться между различными API. .
Spark SQL имеет следующие характеристики:
- Интеграция — бесшовная интеграция SQL-запросов с программами Spark. Spark SQL может запрашивать структурированные данные как RDD (устойчивые распределенные наборы данных) Spark и интегрирует API в такие языки, как Scala, Java, Python и R. Эта интеграция позволяет разработчикам выполнять сложные алгоритмы анализа, просто выполняя SQL-запросы.
- Унифицированный доступ к данным. Через единый интерфейс, предоставляемый Schema-RDD для эффективной обработки структурированных данных, Spark SQL может запрашивать данные из нескольких источников данных, таких как таблицы Hive, паркет или файлы JSON, а также может загружать данные в эти источники данных.
- Совместимость с Hive-Hive запросы к существующим хранилищам данных могут выполняться без изменений. Spark SQL повторно использует интерфейс Hive и хранилище метаданных и полностью совместим с существующими данными, запросами и пользовательскими функциями Hive.
- Стандартный уровень соединения — используйте соединение JDBC или ODBC. Spark SQL предоставляет стандартные соединения JDBC и ODBC.
- Масштабируемость. Интерактивный запрос и пакетный запрос используют один и тот же механизм выполнения. Spark SQL использует модель RDD для обеспечения отказоустойчивости и масштабируемости.
Архитектура Spark SQL показана на рисунке ниже.
Эта архитектура включает три уровня: API языка, RDD схемы и источники данных.
- Language API-Spark SQL совместим с несколькими языками и предоставляет API для этих языков.
- Схема RDD-Схема RDD — это RDD, в котором хранятся объекты строк, каждый объект Row представляет собой строку записей. Схема RDD также содержит информацию о структуре записи (то есть поля данных), которые могут использовать информацию о структуре для эффективного хранения данных. Схема RDD поддерживает операции запросов SQL.
- Источники данных. Как правило, источником данных Spark является текстовый файл или файл Avro, в то время как источник данных Spark SQL отличается. Источником данных могут быть файлы Parquet, документы JSON, таблицы Hive или базы данных Cassandra.
Сравнение Hive, Spark SQL и Impala
(1) Функция
Hive:
- Это инструмент для упрощения извлечения, преобразования и загрузки данных.
- Обеспечить механизм для добавления структуры к данным в разных форматах
- Вы можете напрямую получить доступ к файлам, хранящимся в HDFS, или вы можете получить доступ к данным HBase
- Выполнить запрос через MapReduce
- Hive определяет простой SQL-подобный язык запросов под названием HiveQL. Пользователи, знакомые с SQL, могут использовать его для запроса данных. В то же время язык HiveQL также позволяет программистам, знакомым с вычислительной средой MapReduce, добавлять настраиваемые плагины преобразователя и редуктора для выполнения сложного анализа, который не поддерживается встроенными функциями языка.
- Пользователи могут определять свою собственную скалярную функцию (UDF), агрегатную функцию (UDAF) и табличную функцию (UDTF).
- Поддержка сжатия индекса и индекса растрового изображения
- Поддержка нескольких форматов файлов или типов хранения, таких как текст, RCFile, HBase, ORC и т. Д.
- Используйте СУБД для хранения метаданных, что значительно сокращает время, необходимое для семантической проверки во время выполнения запроса.
- Поддержка таких алгоритмов, как DEFLATE, BWT или snappy, для управления данными, хранящимися в экосистеме Hadoop.
- Большое количество встроенных функций даты, числа, строк, агрегирования, анализа и поддержка встроенных функций расширения UDF.
- HiveQL неявно преобразуется в задания MapReduce или Spark.
Spark SQL:
- Поддерживает несколько форматов файлов, таких как Parquet, Avro, Text, JSON, ORC и т. Д.
- Поддержка операций с данными, хранящихся в HDFS, HBase, Amazon S3
- Поддержка типичных методов кодирования сжатия Hadoop, таких как snappy, lzo, gzip и т. Д.
- Обеспечьте безопасную аутентификацию с помощью «общего секрета»
- Поддержка SSL-шифрования Akka и протокола HTTP
- Сохранить журнал событий
- Поддержка UDF
- Поддерживает управление выделением памяти для параллельных запросов и заданий (можно указать, что RDD хранится только в памяти или только на диске, или и в памяти, и на диске)
- Поддержка кеширования данных в памяти
- Поддержка вложенной структуры
Impala:
- Поддерживает несколько форматов файлов, таких как Parquet, Avro, Text, RCFile, SequenceFile и т. Д.
- Поддержка операций с данными, хранящихся в HDFS, HBase, Amazon S3
- Поддержка нескольких методов кодирования сжатия: Snappy (эффективный баланс между степенью сжатия и скоростью распаковки), Gzip (сжатие архивных данных с максимальной степенью сжатия), Deflate (текстовые файлы не поддерживаются), Bzip2, LZO (только текстовые файлы)
- Поддержка UDF и UDAF
- Автоматически объединять таблицы в наиболее эффективном порядке
- Позволяет определить приоритетную стратегию организации очереди для запросов.
- Поддержка многопользовательских одновременных запросов
- Поддержка кеширования данных
- Предоставлять статистику вычислений (ВЫЧИСЛИТЬ СТАТИСТИКУ)
- Предоставление оконных функций (агрегирование OVER PARTITION, RANK, LEAD, LAG, NTILE и т. Д.) Для поддержки расширенных функций анализа
- Поддержка использования дисков для подключения и агрегирования и переключение на дисковые операции при переполнении памяти, используемой операцией.
- Разрешить подзапросы в предложении where
- Разрешить инкрементную статистику — выполнять статистические вычисления только для новых или измененных данных
- Поддержка сложных вложенных запросов к картам, структурам и массивам
- Вы можете использовать импалу для вставки или обновления HBase
(2) Архитектура
Hive:
Построенный на основе Hadoop, он запрашивает и управляет компонентами хранилища данных для больших наборов данных в распределенном хранилище. На нижнем уровне используется вычислительная среда MapReduce, а запросы Hive преобразуются в коды MapReduce и выполняются. Рекомендуется использовать СУБД для хранения метаданных в производственных средах. Поддержка JDBC, ODBC, CLI и других методов подключения.
Spark SQL:
Базовый уровень использует вычислительную среду Spark для создания ориентированного ациклического графа, который более гибок, чем MapReduce. Spark SQL использует Schema RDD в качестве ядра, стирая грань между RDD и реляционными таблицами. Схема RDD — это RDD, состоящий из объектов Row со структурной информацией, содержащей каждый тип данных столбца. Spark SQL повторно использует хранилище метаданных Hive. Он поддерживает JDBC, ODBC, CLI и другие методы подключения, а также предоставляет API-интерфейсы на нескольких языках.
Impala:
Нижний уровень использует технологию MPP для поддержки быстрых интерактивных запросов SQL. Совместное использование хранилища метаданных с Hive. Impalad — это основной процесс, отвечающий за получение запросов и распределение задач по множеству узлов данных. Процесс с сохранением состояния отвечает за мониторинг всех процессов Impalad и сообщение о состоянии каждого процесса Impalad узлам в кластере. Каталогизированный процесс отвечает за широковещательную передачу и уведомление последней информации о метаданных.
(3) Сцена
Hive:
Применимые сценарии:
- Периодически конвертируйте большой объем данных, например: импортируйте данные OLTP каждую ночь и преобразуйте их в звездообразный режим; конвертируйте данные пакетами каждый час и т. Д.
- Интегрируйте устаревшие форматы данных, например: конвертируйте данные CSV в Avro; конвертируйте определяемый пользователем внутренний формат в Parquet и т. Д.
- Например, бизнес-аналитика: в сочетании с Tableau для исследования данных; в сочетании с Micro Strategy для создания отчетов и т. Д.
- Интерактивный запрос, например: запрос OLAP.
Spark SQL:
Применимые сценарии:
- Извлеките часть данных из хранилища данных Hive и используйте Spark для анализа.
- Бизнес-аналитика и интерактивные запросы.
Impala:
Применимые сценарии:
- Время отклика в секундах
- OLAP
- Интерактивный запрос
Сравнение производительности Hive, SparkSQL и Impala
(1) Сравнительный тест производительности, проведенный Cloudera в 2014 г., исходная ссылка:http://blog.cloudera.com/blog/2014/09/new-benchmarks-for-sql-on-hadoop-impala-1-4-widens-the-performance-gap/
Давайте сначала посмотрим на результаты теста:
- Для однопользовательских запросов Impala работает до 13 раз быстрее, чем другие решения, и в среднем в 6,7 раза быстрее.
- Для многопользовательских запросов разрыв еще больше увеличился: Impala работает до 27,4 раз быстрее, чем другие решения, и в среднем в 18 раз быстрее.
Давайте посмотрим, как проводится этот тест.
Конфигурация:
Все тесты выполняются в идентичном кластере из 21 узла, и каждый узел оснащен только 64 ГБ памяти. Причина, по которой память невелика, состоит в том, чтобы исключить заблуждение, что Impala может иметь хорошую производительность только на очень большой памяти:
- Два физических процессора, каждый по 12 ядер, Intel Xeon CPU E5-2630L 0 с частотой 2,00 ГГц
- 12 дисков, каждый диск 932 ГБ, 1 используется как ОС, остальные используются как HDFS
- 64 ГБ памяти на узел
Сравнить продукты:
- Impala 1.4.0
- Hive-on-Tez 0.13
- Spark SQL 1.1
- Presto 0.74
Спросите:
- Объем данных на 21 узле — 15T
- Сценарий тестирования взят из TPC-DS, открытого эталонного теста поддержки принятия решений (включая интерактивные, отчетные и аналитические запросы).
- Поскольку для других движков, кроме Impala, нет оптимизатора на основе затрат, все запросы, используемые в этом тесте, используют стандартные соединения SQL-92.
- Используя унифицированный метод кодирования сжатия Snappy, каждый движок использует свой собственный оптимальный формат файла, Impala и Spark SQL используют Parquet, Hive-on-Tez использует ORC, а Presto использует RCFile.
- Запускайте и настраивайте каждый двигатель несколько раз
результат:
Один пользователь показан на рисунке ниже.
На рисунке ниже показано несколько пользователей.
Скорость выполнения запроса показана на рисунке ниже.
Сама Impala является флагманским продуктом Cloudera, поэтому было бы предвзято просто слушать ее. Давайте посмотрим на еще один тест SAS.
(2) Сравнительный тест Impala и Hive, проведенный SAS в 2013 г.
аппаратное обеспечение:
- Dell M1000e server rack
- 10 Dell M610 blades
- Juniper EX4500 10 GbE switch
- Intel Xeon X5667 3.07GHz processor
- Dell PERC H700 Integrated RAID controller
- Disk size: 543 GB
- FreeBSD iSCSI Initiator driver
- HP P2000 G3 iSCSI dual controller
- Memory: 94.4 GB
программного обеспечения:
- Linux 2.6.32
- Apache Hadoop 2.0.0
- Apache Hive 0.10.0
- Impala 1.0
- Apache MapReduce 0.20.2
данные:
Модель данных показана на рисунке ниже.
Объем данных каждой таблицы показан на рисунке ниже.
В таблице PAGE_CLICK_FLAT используется формат файла сжатой последовательности размером 124,59 ГБ.
Спросите:
Используются следующие 5 предложений запроса.
-- What are the most visited top-level directories on the customer support website for a given week and year? select top_directory, count(*) as unique_visits from (select distinct visitor_id, split(requested_file, '[\\/]')[1] as top_directory from page_click_flat where domain_nm = 'support.sas.com' and flash_enabled='1' and weekofyear(detail_tm) = 48 and year(detail_tm) = 2012 ) directory_summary group by top_directory order by unique_visits; -- What are the most visited pages that are referred from a Google search for a given month? select domain_nm, requested_file, count(*) as unique_visitors, month from (select distinct domain_nm, requested_file, visitor_id, month(detail_tm) as month from page_click_flat where domain_nm = 'support.sas.com' and referrer_domain_nm = 'www.google.com' ) visits_pp_ph_summary group by domain_nm, requested_file, month order by domain_nm, requested_file, unique_visitors desc, month asc; -- What are the most common search terms used on the customer support website for a given year? select query_string_txt, count(*) as count from page_click_flat where query_string_txt <> '' and domain_nm='support.sas.com' and year(detail_tm) = '2012' group by query_string_txt order by count desc; -- What is the total number of visitors per page using the Safari browser? select domain_nm, requested_file, count(*) as unique_visitors from (select distinct domain_nm, requested_file, visitor_id from page_click_flat where domain_nm='support.sas.com' and browser_nm like '%Safari%' and weekofyear(detail_tm) = 48 and year(detail_tm) = 2012 ) uv_summary group by domain_nm, requested_file order by unique_visitors desc; -- How many visitors spend more than 10 seconds viewing each page for a given week and year? select domain_nm, requested_file, count(*) as unique_visits from (select distinct domain_nm, requested_file, visitor_id from page_click_flat where domain_nm='support.sas.com' and weekofyear(detail_tm) = 48 and year(detail_tm) = 2012 and seconds_spent_on_page_cnt > 10; ) visits_summary group by domain_nm, requested_file order by unique_visits desc; результат:
Сравнение времени выполнения запроса между Hive и Impala показано на рисунке ниже.
Вы можете видеть, что запросы 1, 2 и 4 Impala намного быстрее, чем Hive, а запросы 3 и 5 Impala намного медленнее, чем Hive. Этот тест может быть более объективным, и он также иллюстрирует проблему со стороны.Не доверяйте данным, заявленным производителем, но делайте выводы на основе вашей реальной тестовой ситуации.
Русские Блоги
1. В младшей версии hive есть только две вычислительные машины [mr, tez]! ! !
2. В старшей версии hive есть три вычислительных машины [mr, spark, tez]! ! !
Переключить двигатель
1) Настройте механизм расчета mapreduce.
set hive.execution.engine=mr; 2) Настроить искровой вычислительный движок
set hive.execution.engine=spark; 3) Настроить вычислитель tez
set hive.execution.engine=tez; Примечание: При включении искрового двигателя на кластере должна быть установлена искра, а версии улей и искры должны совпадать! ! !
apache hive — What is hive — hive tutorial — hadoop hive — hadoop hive — hiveql

hive can be used for real time queries what is hive in hadoop hive vs hbase what is pig in hadoop hive architecture components of hive hive can be installed in apache hive tutorial apache hive components hive architecture pdf hive architecture ppt purpose of hive in the hadoop architecture pig architecture
-
INTERVIEW TIPS
- Final Year Projects
- HR Interview Q&A
- GD Interview
- Resume Samples
- Engineering
- Aptitude
- Reasoning
- Company Questions
- Country wise visa
- Interview Dress Code CAREER GUIDANCE
- Entrance Exam
- Colleges
- Admission Alerts
- ScholarShip
- Education Loans
- Letters
- Learn Languages
Big Data от A до Я. Часть 5.1: Hive — SQL-движок над MapReduce
Привет, Хабр! Мы продолжаем наш цикл статьей, посвященный инструментам и методам анализа данных. Следующие 2 статьи нашего цикла будут посвящены Hive — инструменту для любителей SQL. В предыдущих статьях мы рассматривали парадигму MapReduce, и приемы и стратегии работы с ней. Возможно многим читателям некоторые решения задач при помощи MapReduce показались несколько громоздкими. Действительно, спустя почти 50 лет после изобретения SQL, кажется довольно странным писать больше одной строчки кода для решения задач вроде «посчитай мне сумму транзакций в разбивке по регионам».
С другой стороны, классические СУБД, такие как Postgres, MySQL или Oracle не имеют такой гибкости в масштабировании при обработке больших массивов данных и при достижении объема большего дальнейшая поддержка становится большой головоной болью.

Собственно, Apache Hive был придуман для того чтобы объединить два этих достоинства:
- Масштабируемость MapReduce
- Удобство использования SQL для выборок из данных.
Общее описание
Hive появился в недрах компании Facebook в 2007 году, а через год исходники hive были открыты и переданы под управление apache software foundation. Изначально hive представлял собой набор скриптов поверх hadoop streaming (см 2-ю статью нашего цикла), позже развился в полноценный фреймворк для выполнения запросов к данным поверх MapReduce.
Актуальная версия apache hive(2.0) представляет собой продвинутый фреймворк, который может работать не только поверх фреймворка Map/Reduce, но и поверх Spark(про спарк у нас будут отдельные статьи в цикле), а также Apache Tez.
Apache hive используют в production такие компании как Facebook, Grooveshark, Last.Fm и многие другие. Мы в Data-Centric alliance используем HIve в качестве основного хранилища логов нашей рекламной платформы.
Архитектура
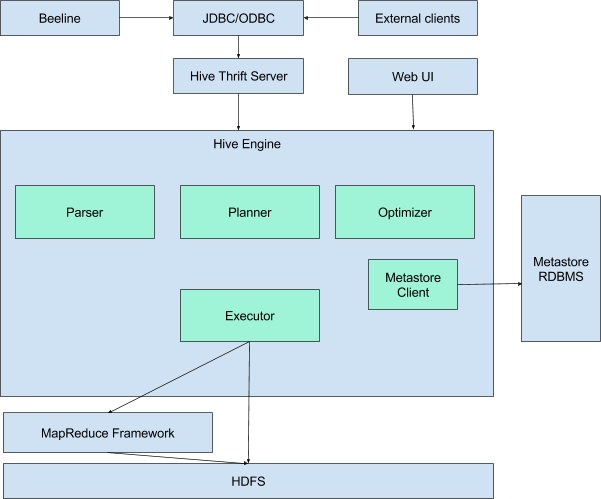
Hive представляет из себя движок, который превращает SQL-запросы в цепочки map-reduce задач. Движок включает в себя такие компоненты, как Parser(разбирает входящие SQL-запрсоы), Optimimer(оптимизирует запрос для достижения большей эффективности), Planner (планирует задачи на выполнение) Executor(запускает задачи на фреймворке MapReduce.
Для работы hive также необходимо хранилище метаданных. Дело в том что SQL предполагает работу с такими объектами как база данных, таблица, колонки, строчки, ячейки и тд. Поскольку сами данные, которые использует hive хранятся просто в виде файлов на hdfs — необходимо где-то хранить соответствие между объектами hive и реальными файлами.
В качестве metastorage используется обычная реляционная СУБД, такая как MySQL, PostgreSQL или Oracle.
Command line interface
Для того чтобы попробовать работу с hive проще всего воспользоваться его командной строкой. Современная утилита для работы с hive называется beeline (привет нашим партнёрам из одноименного оператора 🙂 ) Для этого на любой машине в hadoop-кластере (см. наш туториал по hadoop) с установленным hive достаточно набрать команду.
$beelineДалее необходимо установить соединение с hive-сервером:
beeline> !connect jdbc:hive2://localhost:10000/default root root Connecting to jdbc:hive2://localhost:10000/default Connected to: Apache Hive (version 1.1.0-cdh5.7.0) Driver: Hive JDBC (version 1.1.0-cdh5.7.0) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://localhost:10000/default>root root — в данном контексте это имя пользователя и пароль. После этого вы получите командную строку, в которой можно вводить команды hive .
Также иногда бывает удобно не вводить sql-запросы в командную строку beeline, а предварительно сохранить и редактировать их в файле, а потом выполнить все запросы из файла. Для этого нужно выполнить beeline с параметрами подключения к базе данных и параметром -f указывающим имя файла, содержащего запросы:
beeline -u jdbc:hive2://localhost:10000/default -n root -p root -f sorted.sqlData Units
При работе с hive можно выделить следующие объекты которыми оперирует hive:
- База данных
- Таблица
- Партиция (partition)
- Бакет (bucket)
База данных
База данных представляет аналог базы данных в реляционных СУБД. База данных представляет собой пространство имён, содержащее таблицы. Команда создания новой базы данных выглядит следующим образом:
CREATE DATABASE|SCHEMA [IF NOT EXISTS]
Database и Schema в данном контексте это одно и тоже. Необязательная добавка IF NOT EXISTS как не сложно догадаться создает базу данных только в том случае если она еще не существует.
Пример создания базы данных:
CREATE DATABASE userdb;Для переключения на соответствующую базу данных используем команду USE:
USE userdb;Таблица
Таблица в hive представляет из себя аналог таблицы в классической реляционной БД. Основное отличие — что данные hive’овских таблиц хранятся просто в виде обычных файлов на hdfs. Это могут быть обычные текстовые csv-файлы, бинарные sequence-файлы, более сложные колоночные parquet-файлы и другие форматы. Но в любом случае данные, над которыми настроена hive-таблица очень легко прочитать и не из hive.
Таблицы в hive бывают двух видов:
Классическая таблица, данные в которую добавляются при помощи hive. Вот пример создания такой таблицы (источник примера):
CREATE TABLE IF NOT EXISTS employee ( eid int, name String, salary String, destination String) COMMENT 'Employee details' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS TEXTFILE;Тут мы создали таблицу, данные в которой будут храниться в виде обычных csv-файлов, колонки которой разделены символом табуляции. После этого данные в таблицу можно загрузить. Пусть у нашего пользователя в домашней папке на hdfs есть (напоминаю, что загрузить файл можно при помощи hadoop fs -put) файл sample.txt вида:
1201 Gopal 45000 Technical manager 1202 Manisha 45000 Proof reader 1203 Masthanvali 40000 Technical writer 1204 Kiran 40000 Hr Admin 1205 Kranthi 30000 Op AdminЗагрузить данные мы сможем при помощи следующей команды:
LOAD DATA INPATH '/user/root/sample.txt' OVERWRITE INTO TABLE employee;После hive переместит данныe, хранящемся в нашем файле в хранилище hive. Убедиться в этом можно прочитав данные напрямую из файла в хранилище hive в hdfs:
[root@quickstart ~]# hadoop fs -text /user/hive/warehouse/userdb.db/employee/* 1201 Gopal 45000 Technical manager 1202 Manisha 45000 Proof reader 1203 Masthanvali 40000 Technical writer 1204 Kiran 40000 Hr Admin 1205 Kranthi 30000 Op AdminКлассические таблицы можно также создавать как результат select-запроса к другим таблицам:
0: jdbc:hive2://localhost:10000/default> CREATE TABLE big_salary as SELECT * FROM employee WHERE salary > 40000; 0: jdbc:hive2://localhost:10000/default> SELECT * FROM big_salary; +-----------------+------------------+--------------------+-------------------------+--+ | big_salary.eid | big_salary.name | big_salary.salary | big_salary.destination | +-----------------+------------------+--------------------+-------------------------+--+ | 1201 | Gopal | 45000 | Technical manager | | 1202 | Manisha | 45000 | Proof reader | +-----------------+------------------+--------------------+-------------------------+--+Кстати говоря, SELECT для создания таблицы в данном случае уже запустит mapreduce-задачу.
Внешняя таблица, данные в которую загружаются внешними системами, без участия hive. Для работы с внешними таблицами при создании таблицы нужно указать ключевое слово EXTERNAL, а также указать путь до папки, по которому хранятся файлы:
CREATE EXTERNAL TABLE IF NOT EXISTS employee_external ( eid int, name String, salary String, destination String) COMMENT 'Employee details' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS TEXTFILE LOCATION '/user/root/external_files/';После этого таблицей можно пользоваться точно так же как и обычными таблицами hive. Самое удобное в этом, что вы можете просто скопировать файл в нужную папочку в hdfs, а hive будет автоматом подхватывать новые файлы при запросах к соответствующей таблице. Это очень удобно при работе например с логами.
Партиция (partition)
Так как hive представляет из себя движок для трансляции SQL-запросов в mapreduce-задачи, то обычно даже простейшие запросы к таблице приводят к полному сканированию данных в этой таблицы. Для того чтобы избежать полного сканирования данных по некоторым из колонок таблицы можно произвести партиционирование этой таблицы. Это означает, что данные относящиеся к разным значениям будут физически храниться в разных папках на HDFS.
Для создания партиционированной таблицы необходимо указать по каким колонкам будет произведено партиционирование:
CREATE TABLE IF NOT EXISTS employee_partitioned ( eid int, name String, salary String, destination String) COMMENT 'Employee details' PARTITIONED BY (birth_year int, birth_month string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS TEXTFILE;При заливке данных в такую таблицу необходимо явно указать, в какую партицию мы заливаем данные:
LOAD DATA INPATH '/user/root/sample.txt' OVERWRITE INTO TABLE employee_partitioned PARTITION (birth_year=1998, birth_month='May');Посмотрим теперь как выглядит структура директорий:
[root@quickstart ~]# hadoop fs -ls /user/hive/warehouse/employee_partitioned/ Found 1 items drwxrwxrwx - root supergroup 0 2016-05-08 15:03 /user/hive/warehouse/employee_partitioned/birth_year=1998 [root@quickstart ~]# hadoop fs -ls -R /user/hive/warehouse/employee_partitioned/ drwxrwxrwx - root supergroup 0 2016-05-08 15:03 /user/hive/warehouse/employee_partitioned/birth_year=1998 drwxrwxrwx - root supergroup 0 2016-05-08 15:03 /user/hive/warehouse/employee_partitioned/birth_year=1998/birth_month=May -rwxrwxrwx 1 root supergroup 161 2016-05-08 15:03 /user/hive/warehouse/employee_partitioned/birth_year=1998/birth_month=May/sample.txtВидно, что структура директорий выглядит таким образом, что каждой партиции соответствует отдельная папка на hdfs. Теперь, если мы будем запускать какие-либо запросы, у казав в условии WHERE ограничение на значения партиций — mapreduce возьмет входные данные только из соответствующих папок.
В случае External таблиц партиционирование работает аналогичным образом, но подобную структуру директорий придется создавать вручную.
Партиционирование очень удобно например для разделения логов по датам, так как правило любые запросы за статистикой содержат ограничение по датам. Это позволяет существенно сократить время запроса.
Бакет
Партиционирование помогает сократить время обработки, если обычно при запросах известны ограничения на значения какого-либо столбца. Однако оно не всегда применимо. Например — если количество значений в столбце очень велико. Напрмер — это может быть ID пользователя в системе, содержащей несколько миллионов пользователей.
В этом случае на помощь нам придет разделение таблицы на бакеты. В один бакет попадают строчки таблицы, для которых значение совпадает значение хэш-функции вычисленное по определенной колонке.
При любой работе с бакетированными таблицами необходимо не забывать включать поддержку бакетов в hive (иначе hive будет работать с ними как с обычными таблицами):
set hive.enforce.bucketing=true;Для создания таблицы разбитой на бакеты используется конструкция CLUSTERED BY
set hive.enforce.bucketing=true; CREATE TABLE employee_bucketed ( eid int, name String, salary String, destination String) CLUSTERED BY(eid) INTO 10 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS TEXTFILE;Так как команда Load используется для простого перемещения данных в хранилище hive — в данном случае для загрузки она не подходит, так как данные необходимо предобработать, правильно разбив их на бакеты. Поэтому их нужно загрузить при помощи команды INSERT из другой таблицы(например из внешней таблицы):
set hive.enforce.bucketing=true; FROM employee_external INSERT OVERWRITE TABLE employee_bucketed SELECT *;После выполнения команды убедимся, что данные действительно разбились на 10 частей:
[root@quickstart ~]# hadoop fs -ls /user/hive/warehouse/employee_bucketed Found 10 items -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000000_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000001_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000002_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000003_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000004_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000005_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000006_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000007_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000008_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000009_0Теперь при запросах за данными, относящимися к определенному пользователю, нам не нужно будет сканировать всю таблицу, а только 1/10 часть этой таблицы.
Checklist по использованию hive
Теперь мы разобрали все объекты, которыми оперирует hive. После того как таблицы созданы — можно работать с ними, так как с таблицами обычных баз данных. Однако не стоит забывать о том что hive — это все же движок по запуску mapreduce задач над обычными файлами, и полноценной заменой классическим СУБД он не является. Необдуманное использование таких тяжелых команд, как JOIN может привести к очень долгим задачам. Поэтому прежде чем строить вашу архитектуру на основе hive — необходимо несколько раз подумать. Приведем небольшой checklist по использованию hive:
-
Данных которые надо обрабатывать много и они не влазят на диск одной машины (иначе лучше подумать над классическими SQL-системами).
Заключение
В данной статье мы разобрали архитектуру hive, data unit-ы, которыми оперирует hive, привели примеры по созданию и заполнению таблиц hive. В следующей статье цикла мы рассмотрим продвинутые возможности hive, включающие в себя:
- Транзакционную модель
- Индексы
- User-defined функции
- Интеграцию hive с хранилищами данных, отличными от hdfs
Ссылки на предыдущие статьи цикла: