Что такое Pods, Nodes, Containers и Clusters в Kubernetes

Kubernetes (k8s) очень стремительно становится новым стандартом для деплоймента и менеджмента вашего кода в клауде. Вместе с тем, сколько фич предоставляет k8s, для новичка наступает высокий порог входа в новую технологии.
Документация по k8s достаточно обширна и довольно сложно пройти ее всю. Именно по этому эта статья служит неким обобщением для того, чтобы разобрать основные модули kubernetes.
Hardware
Nodes
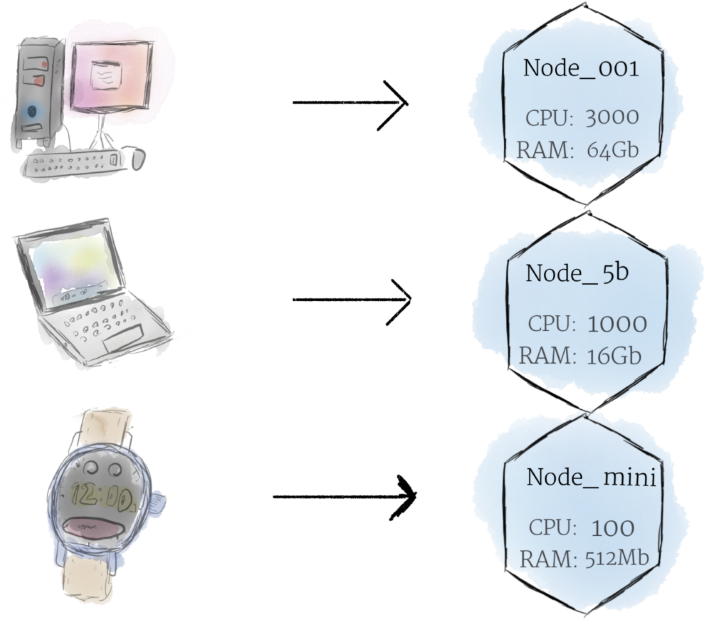
Node — это самая маленькая единица ‘computing hardware в k8s. Это представление одной машины в вашем кластере. В большинстве производственных систем нодой, корее всего, будет либо физическая машина в датацентре, либо виртуальная машина, размещенная на облачном провайдере, таком как Google Cloud Platform, Azure, AWS. Однако, вы можете сделать ноду практически из чего угодно (например Rasbery PI).
Если обсуждать про машину как «ноду», можем разбавить это слоем абстракции, мы можем представлять ее как некий набор CPU, RAM ресурсов которые можно использовать. Таким образом любая такая машина может заменить любую другую машину как k8s кластер.
Cluster
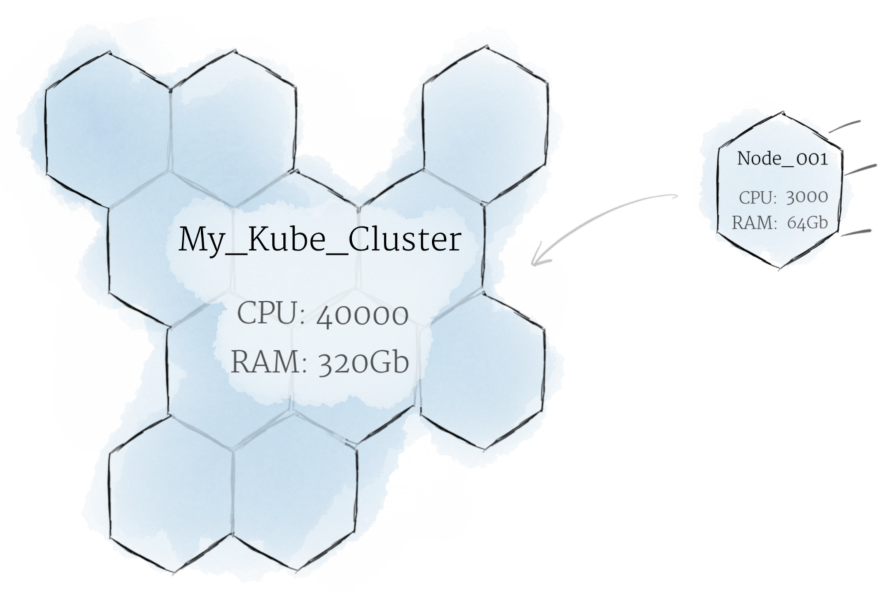
Хотя работа с отдельными нодами может быть полезной, это не путь kubernetes. В общем, вы должны думать о кластере в целом, а не беспокоиться о состоянии отдельных нодов.
В Kubernetes ноды объединяют свои ресурсы для формирования более мощной машины. Когда вы развертываете программы в кластере, он балансирует нагрузку по индивидуальным нодам для вас. Если какие-либо nodes добавляются или удаляются, кластер будет перемещаться по мере необходимости. Для программы или девелопера не должно быть важно, на каких машинах выполняется код в k8s. Можно сравнить такую систему с улием.
Persistent Volumes
Поскольку программы, работающие в вашем кластере, не гарантированно выполняются на определенной ноде, данные не могут быть сохранены в любом произвольном месте в файловой системе. Если программа пытается сохранить данные в файл, но затем перемещается на новую ноду, файл больше не будет там, где программа ожидает его. По этой причине традиционное локальное хранилище, связанное с каждой нодой, рассматривается как временный кэш для хранения программ, но нельзя ожидать, что любые данные, сохраненные локально, сохранятся.
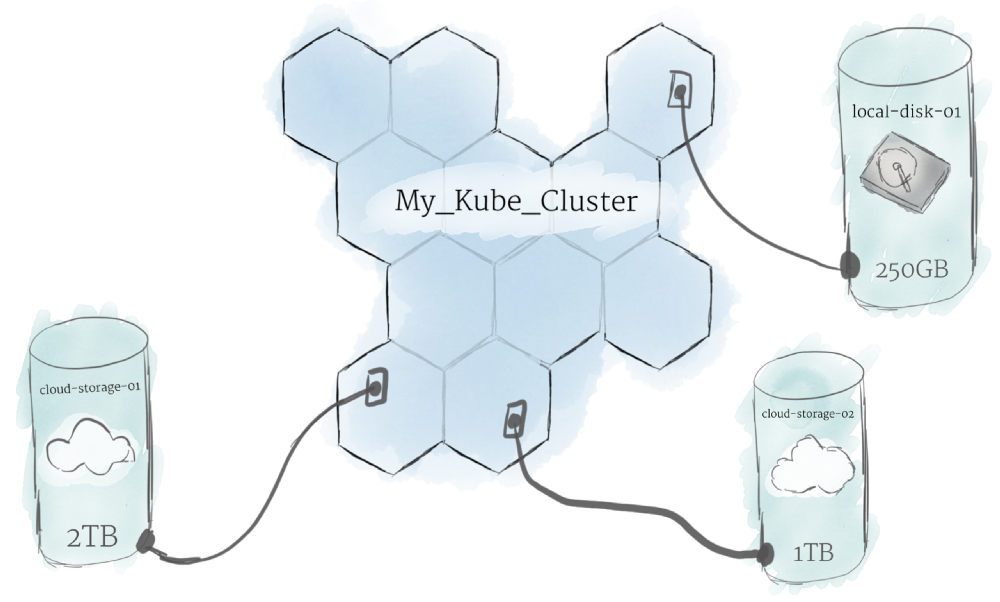
Для постоянного хранения данных Kubernetes использует Persistent Volumes. Хотя ресурсы ЦП и ОЗУ всех нодов эффективно объединяются и управляются кластером, постоянного хранение файлов — нет. Вместо этого локальные или облачные диски могут быть подключены к кластеру как постоянный том (Persistent Volumes). Это можно рассматривать как подключение внешнего жесткого диска к кластеру. Persistent Volumes предоставляют файловую систему, которая может быть подключена к кластеру без привязки к какому-либо конкретному ноду.
Software
Контейнеры
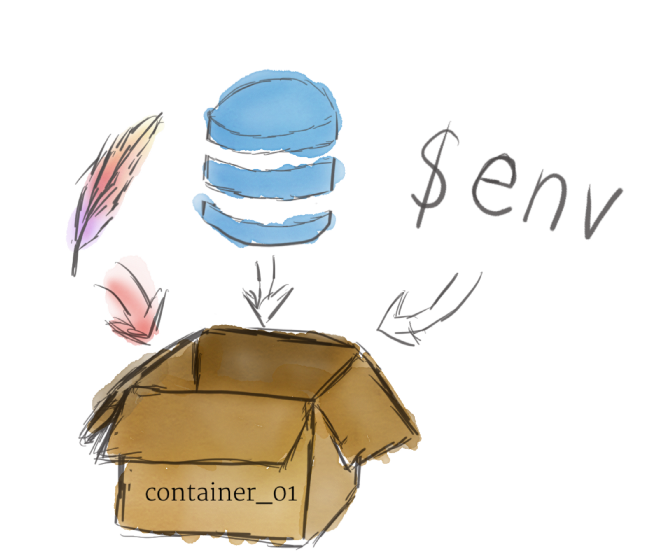
Программы, работающие на Kubernetes, упаковуются в контейнеры. Контейнеры являются общепринятым стандартом, поэтому уже есть много готовых образов, которые можно развернуть в Kubernetes.
Контейнеризация позволяет вам создавать self-contained environments. Любая программа и все ее зависимости могут быть объединены в один файл и затем опубликованы в Интернете. Любой может загрузить контейнер и развернуть его в своей инфраструктуре с минимальными настройками. Создание контейнера может быть сделано и скриптом, позволяя строить CI/CD пайплайны.
Несколько программ могут быть развернуты в одном контейнере, но вы должны ограничить себя одним процессом на контейнер, если это вообще возможно. Лучше иметь много маленьких контейнеров, чем один большой. Если каждый контейнер имеет четкую направленность, обновления легче развертывать, а проблемы легче диагностировать.
Pods
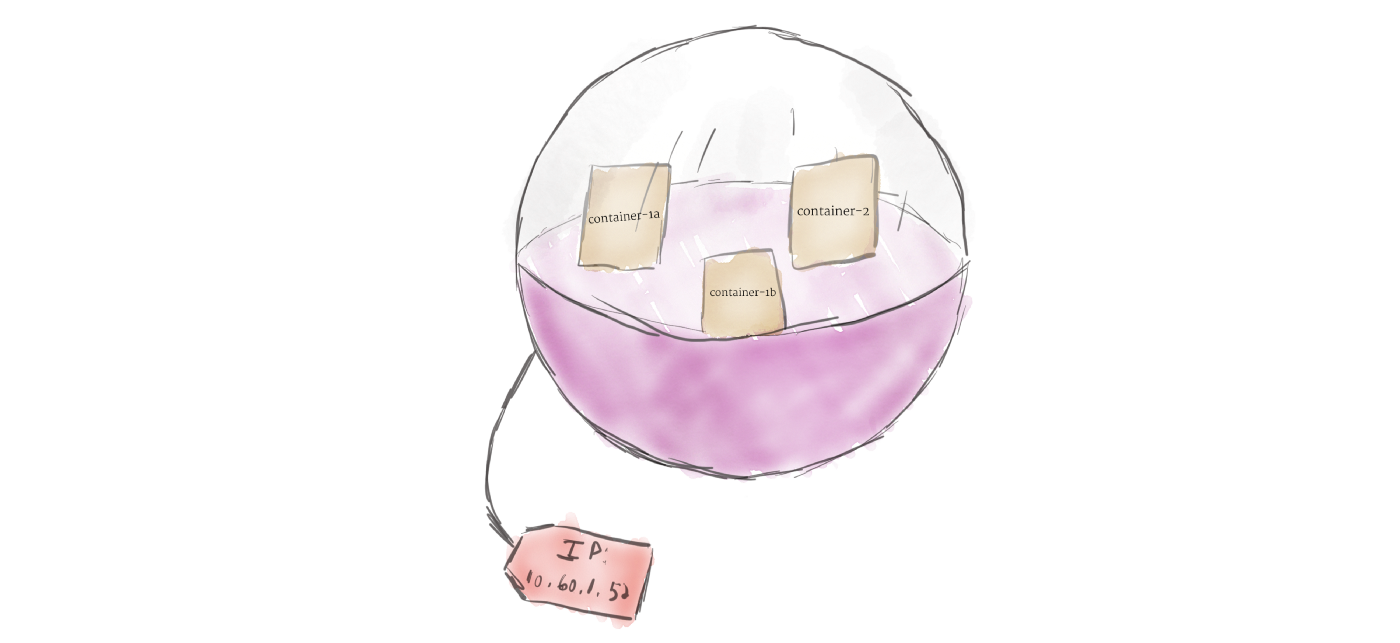
В отличие от других систем, которые вы, возможно, использовали в прошлом, Kubernetes не запускает контейнеры напрямую; вместо этого он упаковывает один или несколько контейнеров в структуру более высокого уровня, называемую pod. Любые контейнеры в одном pod’e будут использовать одни и те же ресурсы и локальную сеть. Контейнеры могут легко связываться с другими контейнерами в том же pod’e, как если бы они находились на одной машине, сохраняя степень изоляции от других pod’ов.
Pod’ы используются как единица репликации в Kubernetes. Если ваше приложение становится слишком популярным, и один экземпляр модуля не может нести нагрузку, Kubernetes можно настроить для развертывания новых реплик вашего модуля в кластере по мере необходимости. Даже если не под большой нагрузкой, в продакшинев любое время можно запустить несколько копий модуля в любое время, чтобы обеспечить балансировку нагрузки и устойчивость к сбоям.
Pod’ы могут содержать несколько контейнеров, но вы должны ограничивать их количество, когда это возможно. Поскольку контейнеры масштабируются как единое целое, все контейнеры в паке должны масштабироваться вместе, независимо от их индивидуальных потребностей. Это приводит к потраченным впустую ресурсам и дорогому счету. Чтобы решить эту проблему, Pod’ы должны оставаться меньше на сколько это возможно, обычно вмещая только основной процесс и его тесно связанные вспомогательные контейнеры (эти вспомогательные контейнеры обычно называют Side-cars).
Deployments
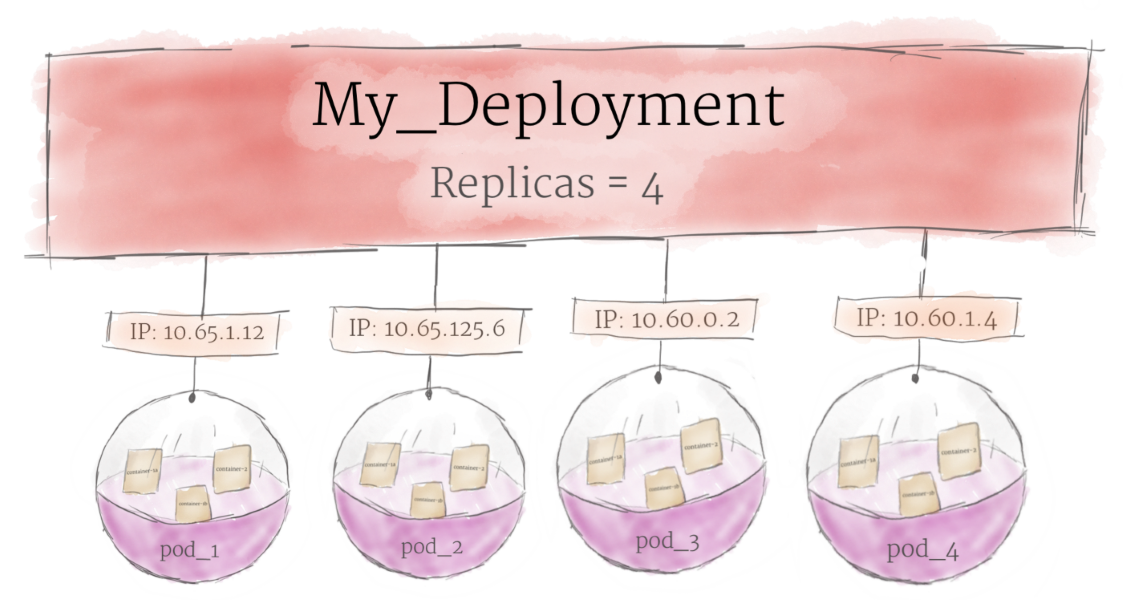
Хотя в Kubernetes pod являются базовой единицей вычислений, они, как правило, не запускаются напрямую в кластере. Вместо этого pod обычно менеджится еще одним уровнем абстракции — deployment.
Основная цель юзать подход с deployment состоит в том, чтобы настроить, сколько реплик pod’а должно работать одновременно. Когда развертывание добавляется в кластер, оно автоматически деплоит требуемое количество pod’ов и отслеживает их. Если pod умирает, deployment автоматически пересоздает его.
Используя deployment, вам не нужно иметь дело с подами вручную. Вы можете просто объявить желаемое состояние системы, и оно будет управляться автоматически.
Ingress
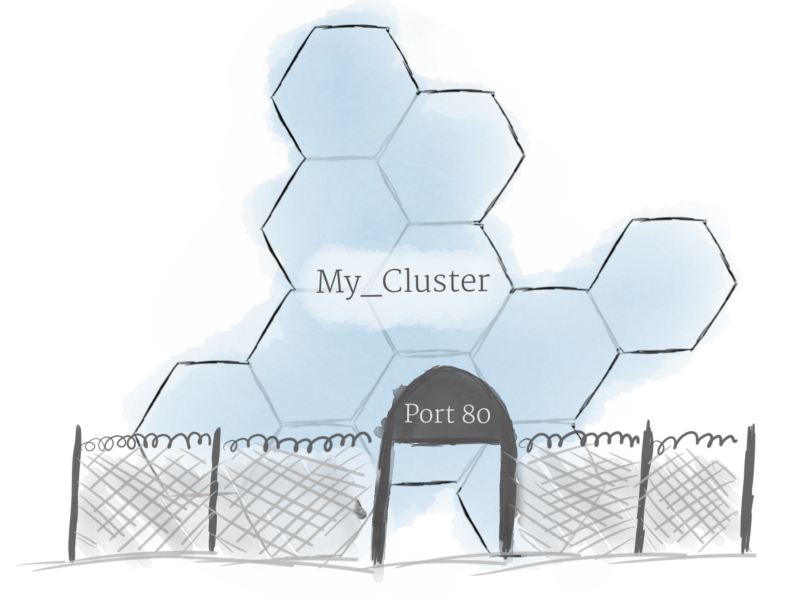
Используя описанные выше концепции, вы можете создать кластер нодов и запустить деплоймент подов в кластере. Однако есть еще одна проблема, которую необходимо решить: разрешить внешний трафик вашему приложению. По умолчанию Kubernetes обеспечивает изоляцию между модулями и внешним миром. Если вы хотите общаться с сервисом, работающим в pod, вам нужно открыть канал для связи. Это называется Ingress.
Есть несколько способов добавить ingress в ваш кластер. Наиболее распространенными способами являются добавление либо ingress controller, либо LoadBalancer. Описание различий и что лучше выбрать выходит за рамки этой статьи, но вы должны держать в голове что вам нужно разобратся с доступом к сервису, если вы хотите работать с k8s.
ELK — Что такое master node и cluster
В elastcsearch каждый экземпляр/сервер с установленным elascsearch называется нодой (node).
Объединение нескольких нод в одну группу, с одинаковым именем называется кластером (cluster). Для создания кластера используется атрибут cluster.name , в котором задаётся имя кластера. Когда ноды присоединяются к кластеру или отключаются от него, кластер автоматически реорганизуется для равномерного распределения данных по доступным узлам.
Минимальное количество нод в кластере равняется 3.
В elastcsearch присутствуют 2 основных механизма коммуникации на сетевом уровне:
- HTTP, который предоставляет REST API Elasticsearch
- Transport используется для связи между узлами в кластере
По умолчанию присваивается значение localhost , с помощью атрибута http.host . Порт по умолчанию является первым доступным между 9200-9299 и настраивается с помощью http.port (можно просто указать один).
Каждый запрос между узлами в кластере происходит именно по **transport **. Например, когда вы, используя get обращаясь к данным, которые лежат на другой ноде будет использоваться **transport ** для получения данных основной нодой.
Транспорт по умолчанию привязывается к localhost и настраивается с помощью transport.host . Порт по умолчанию является первым доступным между 9300-9399 и настраивается с помощью transport.tcp.port .
Специальные значения для network.host
Если вы привязываете и transport ** и **http к одному ip адресу можно воспользоваться одним атрибутом network.host .
Следующие специальные значения могут использоваться для network.host , например если вы не хотите жёстко привязываться к ip адресу .
| Значение | Описание |
|---|---|
| _local_ | Любые адреса обратной связи в системе (например, 127.0.0.1) |
| _site_ | Любой локальный адрес сайта в системе (например, 192.168.1.1) |
| _global_ | Любые глобальные адреса в системе (статика) |
| _[networkInterface]_ | Адрес сетевого интерфейса (например, eth0) |
Модуль обнаружения (Discovery Module) отвечает за обнаружение нод в кластере. Процесс модуля обнаружения помогает нодам находить друг друга. Сами узлы он получает из переменной discovery.seed_hosts .
Когда вы прописали значение для discovery.seed_hosts модуль берёт оттуда каждый хост и проверяет его на доступность, посылая ping запросы . Происходит это на каждой ноде в кластере. Если нода не найдёт ни одной ноды с одинаковым именем кластера ( cluster.name ) она создаст свой кластер.
discovery.seed_hosts: ["host1", "host2", "host3"] discovery.seed_hosts: file.txt sudo cat file.txt host1 host2 host3 Чтобы узнать, как себя чувствует кластер можно проверить состояние кластера (cluster state). С помощью API состояния кластера вы можете получить доступ к метаданным, представляющим состояние всего кластера. А именно набор узлов в кластере, индексы, сопоставления, настройки, выделение сегментов и т. Д.
Вы можете использовать конечную точку _cluster для просмотра состояния кластера:
GET _cluster/state Для укороченного вывода можно использовать:
GET _cluster/health "cluster_name" : "elk-cluster", "status" : "green", "timed_out" : false, "number_of_nodes" : 4, "number_of_data_nodes" : 3, "active_primary_shards" : 43, "active_shards" : 93, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 > В каждом кластере существует мастер нода, через которую выполняются основные операции, например, создание индекса. Состояние кластера хранится на каждом узле, и его может изменить только мастер нода, которая распространяет его на остальные ноды.
Мастер нода выбирается в кластере путем голосования всеми нодами. Для того чтобы какая-либо нода сала мастером за неё должно проголосовать большинство.
Если мастер нода выбывает из кластера начинается новое голосование и выбирается новая мастер нода. После того как старая мастер нода возвращается ей говорится что уже избрана новая мастер нода и ты уже ничего не решаешь, т.е её время прошло. В принципе всё как в жизни.
Обычно лучше иметь нечетное количество узлов, имеющих право быть мастером, чтобы был кворум во время выбора мастера. Если у вас есть четное количество узлов, Elasticsearch исключит один, чтобы избежать ничьих выборов.
Каждый кластер Elasticsearch имеет конфигурацию голосования, которая представляет собой набор узлов для голосования, ответы которых учитываются при принятии таких решений, как выбор нового мастера. Решения принимаются только после того, как большинство (более половины) узлов в конфигурации голосования выберут одного и того же кандидата.
Чтобы получить текущую конфигурацию голосования:
GET _cluster/state?filter_path=metadata.cluster_coordination.last_committed_config "metadata" : "cluster_coordination" : "last_committed_config" : [ #host1 "eiX9un9MSZ-4KsmZyEhE9Q", #host2 "CkcXQe1jRQS9_gCJ3WGkVg", #host3 "MOJcfnA4T82Pmlb2Q6wPyA" ] > > > Для того чтобы задать кто именно имеет права голоса можно воспользоваться переменной cluster.initial_master_nodes.
cluster.initial_master_nodes: ["host1", "host2", "host3"] - Elasticsearch использует два механизма сетевой связи: HTTP для клиентов REST ; и transport для меж узловой связи
- Детали кластера сохраняются в состоянии кластера
- В каждом кластере есть один узел, назначенный мастер нодой
- У вас есть возможность указать какие ноды имеют право голосовать
Поделиться: Twitter Facebook
Пожалуйста подпишитесь: Telegram Youtube

О Ynwasg
Когда-то я тоже был обычным эникейщиком, который ходил и включал мониторы, когда пользователь паниковал что у него комп не включается. Но в своё время мне это надоело, и я пошёл дальше.
Kubernetes 101: Поды, Ноды, Контейнеры, и Кластеры.
Kubernetes быстро становится новым стандартом для развертывания и управления программным обеспечением в облаке. Однако со всей мощью, которую предоставляет Kubernetes, придется пройти крутую кривую обучения. Новичку попытка разобрать официальную документацию может быть непосильной. Система состоит из множества разных частей, и бывает сложно определить, какие из этих частей подходят для вашего варианта использования. В этом сообщении в блоге будет представлен упрощенный взгляд на Kubernetes, но в нем будет предпринята попытка дать общий обзор наиболее важных компонентов, и того, как они взаимодействуют друг с другом.
Во-первых, давайте посмотрим, как представлено оборудование
Аппаратное обеспечение
Узлы (Ноды)
Узел — это наименьшая единица вычислительного оборудования в Kubernetes. Это представление одной машины в вашем кластере. В большинстве производственных систем узел, скорее всего, будет либо физической машиной в центре обработки данных, либо виртуальной машиной, размещенной у облачного провайдера, такого как Google Cloud Platform . Однако не позволяйте условностям ограничивать вас; теоретически можно сделать узел практически из чего угодно .
Представление о машине как об «узле» позволяет нам добавить слой абстракции. Теперь вместо того, чтобы беспокоиться об уникальных характеристиках каждой отдельной машины, мы можем просто рассматривать каждую машину как набор ресурсов ЦП и ОЗУ, которые можно использовать. Таким образом, любая машина может заменить любую другую машину в кластере Kubernetes.
Кластер
Хотя работа с отдельными узлами может быть полезна, это не путь Kubernetes. В общем, вы должны думать о кластере в целом, а не беспокоиться о состоянии отдельных узлов.
В Kubernetes узлы объединяют свои ресурсы, чтобы сформировать более мощную машину. Когда вы развертываете программы в кластере, он интеллектуально распределяет работу по отдельным узлам за вас. Если какие-либо узлы будут добавлены или удалены, кластер будет переключаться между работой по мере необходимости. Для программы или программиста не должно иметь значения, на каких машинах фактически выполняется код.
Если такая система, похожая на коллективный разум, напоминает вам Борга из «Звездного пути» , вы не одиноки; «Борг» — это название внутреннего проекта Google , на котором был основан Kubernetes.
Постоянные тома
Поскольку программы, работающие в вашем кластере, не гарантируют работу на определенном узле, данные не могут быть сохранены в любом произвольном месте в файловой системе. Если программа попытается сохранить данные в файл на потом, но затем будет перемещена на новый узел, файл больше не будет находиться там, где программа ожидает его видеть. По этой причине традиционное локальное хранилище, связанное с каждым узлом, рассматривается как временный кэш для хранения программ, но нельзя ожидать, что любые данные, сохраненные локально, сохранятся.
Для постоянного хранения данных Kubernetes использует постоянные тома . В то время как ресурсы ЦП и ОЗУ всех узлов эффективно объединены и управляются кластером, постоянное хранилище файлов — нет. Вместо этого локальные или облачные диски могут быть подключены к кластеру как постоянный том. Это можно рассматривать как подключение внешнего жесткого диска к кластеру. Постоянные тома предоставляют файловую систему, которую можно подключить к кластеру без привязки к какому-либо конкретному узлу.
Программное обеспечение
Контейнеры
Программы, работающие в Kubernetes, упакованы в контейнеры Linux . Контейнеры являются общепринятым стандартом, поэтому уже существует множество готовых образов , которые можно развернуть в Kubernetes.
Контейнеризация позволяет создавать автономные среды выполнения Linux. Любая программа и все ее зависимости могут быть объединены в один файл, а затем опубликованы в Интернете. Любой может скачать контейнер и развернуть его в своей инфраструктуре с минимальной настройкой. Создание контейнера может быть выполнено программно, что позволяет формировать мощные конвейеры CI и CD .
В один контейнер можно добавить несколько программ, но по возможности следует ограничиться одним процессом на контейнер. Лучше иметь много маленьких контейнеров, чем один большой. Если каждый контейнер имеет четкую направленность, обновления легче развертывать, а проблемы легче диагностировать.
Поды
В отличие от других систем, которые вы могли использовать в прошлом, Kubernetes не запускает контейнеры напрямую; вместо этого он оборачивает один или несколько контейнеров в структуру более высокого уровня, называемую подом . Все контейнеры в одном поде будут использовать одни и те же ресурсы и локальную сеть. Контейнеры могут легко взаимодействовать с другими контейнерами в одном модуле, как если бы они находились на одном компьютере, сохраняя при этом определенную степень изоляции от других.
Поды используются в качестве единицы репликации в Kubernetes. Если ваше приложение становится слишком популярным и один экземпляр модуля не может нести нагрузку, Kubernetes можно настроить для развертывания новых реплик вашего модуля в кластере по мере необходимости. Даже когда нагрузка невелика, стандартно иметь несколько копий модуля, работающих в любое время в производственной системе, чтобы обеспечить балансировку нагрузки и устойчивость к сбоям.
Поды могут содержать несколько контейнеров, но вы должны ограничивать себя, когда это возможно. Поскольку модули масштабируются вверх и вниз как единое целое, все контейнеры в поде должны масштабироваться вместе, независимо от их индивидуальных потребностей. Это приводит к напрасной трате ресурсов и дорогому счету. Чтобы решить эту проблему, поды должны оставаться как можно меньше, как правило, содержащие только основной процесс и его тесно связанные вспомогательные контейнеры (эти вспомогательные контейнеры обычно называются «сайд-карами»).
Деплойменты
Хотя поды являются базовой единицей вычислений в Kubernetes, они обычно не запускаются напрямую в кластере. Вместо этого модули обычно управляются еще одним уровнем абстракции: развертыванием .
Основная цель развертывания — объявить, сколько реплик пода должно работать одновременно. Когда развертывание добавляется в кластер, оно автоматически запускает запрошенное количество модулей, а затем отслеживает их. Если под умирает, развертывание автоматически воссоздает его.
Используя развертывание, вам не нужно иметь дело с подами вручную. Вы можете просто объявить желаемое состояние системы, и оно будет управляться автоматически.
Ingress (Точка входа)
Используя концепции, описанные выше, вы можете создать кластер узлов и запустить развертывание подов в кластере. Однако осталось решить еще одну проблему: разрешить внешний трафик для вашего приложения.
По умолчанию Kubernetes обеспечивает изоляцию между подами и внешним миром. Если вы хотите общаться со службой, работающей в поде, вам нужно открыть канал для связи. Это называется ingress (точка входа).
Есть несколько способов добавить точку входа в ваш кластер. Наиболее распространенными способами являются добавление контроллера Ingress или LoadBalancer . Точные компромиссы между этими двумя вариантами выходят за рамки этой статьи, но вы должны знать, что точка входа — это то, что вам нужно обработать, прежде чем вы сможете экспериментировать с Kubernetes.
Что дальше
То, что описано выше, — это упрощенная версия Kubernetes, но она должна дать вам основы, необходимые для начала экспериментов. Теперь, когда вы понимаете, из чего состоит система, пришло время использовать их для развертывания реального приложения. Ознакомьтесь с Kubernetes 110: Your First Deployment , чтобы начать.
Чтобы поэкспериментировать с Kubernetes локально, Minikube создаст виртуальный кластер на вашем персональном оборудовании. Если вы готовы опробовать облачный сервис, в Google Kubernetes Engine есть коллекция руководств , которые помогут вам начать работу.
Если вы новичок в мире контейнеров и веб-инфраструктуры, я предлагаю ознакомиться с методологией 12 Factor App . Здесь описываются некоторые из лучших практик, которые следует учитывать при разработке программного обеспечения для работы в такой среде, как Kubernetes.
Перевод оригинальной статьи Kubernetes 101: Pods, Nodes, Containers, and Clusters Контент оригинальной статьи принадлежит автору .
Network DataBase (NDB)
MySQL Cluster – система распределенного хранения данных в рамках СУБД MySQL, решение для построения отказоустойчивых систем.
Поскольку Оракл, выкупивший MySQL в своё время, не предоставляет функциональности NDB по умолчанию, проверим её наличие:
Проверка поддержки NDB
mysql> SELECT VERSION()\G *************************** 1. row *************************** VERSION(): 5.6.27-ndb-7.4.9 1 row in set (0.00 sec) Три основных типа нод
Картинка из штатного MySQL Cluster Overview
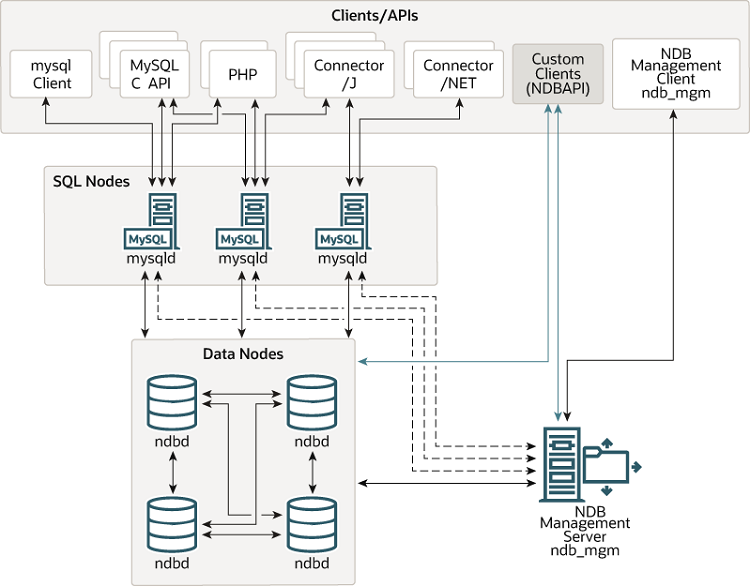
Понятие нода (узел) в контекстке MySQL NDB Cluster
Нодой называется не физический сервер, выполняющий тот либо иной процесс MySQL, а менно сам процесс MySQL/NDB.
Дата-нода (ndb-нода)
Исполняемый процесс ndbd, отвечающий за хранение фрагмента данных в кластере.
Важный параметр кластера NoOfReplicas (число реплик) — число дата-нод на которых хранится каждый конкретный фрагмент. Общее число дата-нод должно быть кратно числу реплик.
Группа нод — несколько нод (число нод в группе равно числу реплик), хранящих идентичную информацию.
NoOfReplicas = 2, число нод — 6.
Каждая таблица разбита на 6 фрагментов (по хэшу первичного ключа), пронумеруем их F1,F2,F3,F4,F5,F6.
6 нод (D1,D2,D3,D4,D5,D6) составляют 3 группы:
- каждая нода первой группы (D1,D2) хранит фрагменты F1,F2
- ноды второй группы D3,D4 хранят фрагменты F3,F4
- ноды третьей группы D5,D6 хранят фрагменты F5,F6
Выход из строя всех нод одной группы приводит к отказу кластера.
SQL-нода (или API-нода)
Исполняемый процесс mysqld.
SQL-нода принимает подключение клиентов и обращается к дата-нодам за данными. Кроме того, каждая SQL-нода вправе хранить собственные не-NDB таблицы (MyISAM, Innodb, . ), как если бы она не входила в кластер.
Управляющая нода (management-нода)
Исполняемый процесс ndbmgmd. Отвечает за конфигурацию кластера, каждая нода обращается к управляющей ноде при подключению к кластеру.
Не управляет транзакциями и другими текущими делами, а концентрируется исключительно на конфигурации.
Потребляет немного системных ресурсов, поэтому часто размещается на одном же физическом сервере с другой нодой.
В случае выхода из строя управляющей ноды, кластер продолжит нормальную работу, но будет невозможен перезапуск нод.
Конфигурация может содержать одну или несколько управляющих нод.
Арбитр и алгортимы арбитража
Арбитр
Одна из нод кластера всегда является арбитром.
Арбитр назначается при запуске кластера и может изменяться в рамках процедуры смены арбитра.
О назначении и смене арбитра можно узнать в логах кластера.
В конфигурации по-умолчанию, арбитром является управляющая нода, однако это не обязательно так.
Арбитром может стать любая управляющая или SQL-нода. У этих нод в конфигурации может быть указан параметр ArbitrationRank (ранг арбитра); значения параметра следующие:
0 - нода никогда не станет арбитром 1 - нода станет арбитром с высоким приоритетом 2 - нода станет арбитром только если нет претендентов с высоким приоритетом В каждый момент в кластере только один арбитр.
Отключение группы нод, split-brain
Арбитр требуется в ситуации, когда от кластера отключились несколько нод.
Пусть кластер физически разделился на 2 кусочка (например, в силу отказа сетевого маршрутиризатора). Возможна ситуация, когда каждый кусочек будет хранить все данные кластера (то есть по крайней мере по одной ноде из каждой группы). Каждый кусочек будет вести себя как полный кластер, что приведет к нарушению целостности данных (например, часть клиентов будет работать с одним кусочком, а часть — с другим).
Такая ситуация потенциально опасна и называется split-brain.
Алгоритм арбитража
Алгоритм арбитража достаточно простой. Он начинает работу сразу после обнаружения фрагментации на каждой работающей дата-ноде осколка кластера.
Вижу ли я по крайней мере одну дата-ноду из каждой группы (иначе говоря — обладает ли видимая часть кластера всеми данными)? Если нет — выключиться. Если да, продолжить алгоритм
Есть ли среди отключившихся дата-нод по одной из ноде из каждой группы (иначе говоря — обладает ли вторая часть всеми данными)? Если нет — значит вторая часть выключится по правилу 1, я могу продолжить работу. Если да, продолжить алгоритм.
Спросить арбитра. Если арбитр недоступен — выключиться. Если арбитр доступен, узнать присутствую ли я в текущей конфигурации, если нет — выключиться, если да — продолжить работу Смена арбитра
Если в результате фрагментации исчез арбитр, то после выполнения алгоритма арбитража, ноды выбирают нового арбитра. Алгоритм выбора в настоящее время простой — выбирается нода с наименьшим номером (nodeid), среди имеющих старший ArbitrationRank.
Примеры
Почему конфигурация из двух физических не является оказоустойчивой?
Рассмотрим следующую конфигурацию, постоенную на двух физических машинах:
Первый сервер — дата-нода 1, SQL-нода 1, управляющая нода 1
Второй сервер — дата-нода 2, SQL-нода 2, (возможно также управляющая нода 2)
Значение NoOfReplicas=2 обеспечивает дублирование данных; обе ноды входят в одну группу. На первый взгляд кажется, что конфигурация откзоустойчива, но на практике это не так. При старте кластера арбитром станет первая управляющая нода. Рассмотрим ситуацию, в которой вышел из строя первый сервер (например выключился, сгорела сетевая карта или вышел из строя порт в маршрутиризаторе). На второй дата-ноде сработает алгоритм арбитража:
Вижу ли по одной ноде из каждой группы? Да, всего одна группа, эта нода — я. Содержит ли отключивашаяся часть полный набор данных? Да, дата-нода 1 содержит копию данных. Спросить арбитра. Арбитр недоступен. Выключиться. Мы видим, что отказ одного сервера приводит к отключению всего кластера.
То же самое произойдет в конфигурации с тремя серверами и NoOfReplicas=3 при отключении сервера, содержащего арбитра.
Простой пример отказоустойчивой конфигурации
Предоставим читателю убедиться в том, что следующая конфигурация является устойчивой по отношению к отказу любого из трех физических серверов:
Первый сервер — дата-нода 1, SQL-нода 1 (ArbitrationRank=0), (NoOfReplicas=2)
Второй сервер — дата-нода 2, SQL-нода 2 (ArbitrationRank=0), (NoOfReplicas=2)
Третий сервер — управляющая нода (ArbitrationRank=2)
К вопросу о тестировании
Избыточность данных еще не гарантирует отказоустойчивость. Обязательно тестируйте конфигурации с использованием описанного выше аглоритма, путем отключения сетевых интерфейсов или путем физического отключения серверов.
К вопросу о производительности
- Таблицы хранятся по нодам построчно (по ключу auto_increment).
- Данные дублируются на нескольких нодах одновременно
- Индексы тоже хранятся на нодах в виде таблиц со всеми вытекающими: распределение между нодами построчно.
Что вытекает из этого? Что бы выполнить полноценный запрос sql с JOIN или несколькими условиями будут выполнены следующие действия:
- по ключу будет найдена нода, хранящая доп. условие;
- на данной ноде будет найдена необходимая запись.
И это для каждого условия, так как разные индексы одной записи могут оказаться на разных нодах.
То есть при одном дополнительном условии (к поиску по автоинкрементному ключу) будет выполнено вместо одного запроса три. При двух дополнительных условиях — пять запросов и т.д.
Производительность кластера из 4-х нод примерно соответствует одному классическому серверу MySQL.
engine_condition_pushdown
ndbcluster более чувствителен к качеству запросов, причём работает несколько факторов
- Оптимизатор в MySQL общий, и он может учесть не все факторы, важные для движка ndb.
- Ошибки оптимизации обходятся дороже. Например, запрос SELECT * FROM table_name WHERE x>y*y;
в innodb выполнится путем перебора всех записей на диске. В ndb необходимо будет еще передать все записи на API-ноду, и только на ней обработать.
В mysql начиная с версии 5.0.3 дата-ноды могут выполнять простую арифметику, это называется «push down conditon», но это только при engine_condition_pushdown=1 и только для простых операций (функции mysql, такие как md5() или sin() на ноды не переносятся).