Когда использовать ООП, а когда — ФП?
Грубо говоря, у ФП и ООП схожие возможности в выражении сложных конструкций и инкапсуляции программ на мелкие куски, которые можно комбинировать между собой.
Самая большая разница между двумя этими «философиями» состоит в том, как данные соотносятся с операциями над данными.
Основной доктриной ООП является то, что данные и операции над ними сильно связаны: объект содержит данные и реализацию операций над данными. Он скрывает всё это от других объектов через интерфейс – набор методов или сообщений, на которые он реагирует. Таким образом, центральной моделью абстракции являются сами данные, спрятанные за небольшим API в виде интерфейса.
При ООП подходе программист составляет новые объекты и расширяет существующие путём добавления к ним методов.
Основной доктриной ФП является то, что данные слабо связаны с функциями. Над одним и тем же набором данных можно совершать разные действия, а центральной моделью абстракции является функция, а не структура данных. Функции прячут их реализацию, а абстракции языка общаются с функциями.
При ФП подходе программист пишет новые функции.
В поединке между медведем и крокодилом решающим фактором выступает местность.
Так когда же одно предпочтительнее другого? Поскольку блог посвящён практическим реализациям, я отметаю теоретические построения вроде возможности механически рассуждать о коде и думать про всякие прагматичные вещи, писать бизнес-код в такой ситуации, когда нужно сделать слишком много всего при недостатке ресурсов и времени.
Может ли одна из двух моделей победить в бизнес окружении? Подумайте хорошенько, пока я заварю себе чашечку эспрессо…
Конечно, в бизнес-программировании доминирует функциональная модель. Сюрприз? Сюрприз, если вы рассматриваете только такие языки, как Java, C++, C# и Ruby.
Если подумать, то всё это ООП – тонкая прослойка для доступа к базам данных и SQL, что на самом деле – функциональный язык. Хотя и возможно управлять базой данных через встроенные процедуры PL/SQL, это создаёт узкое место, и обычно не стоит того.
Главное преимущество реляционных баз данных – возможность работы с требованиями, которые возникнут в будущем. Когда вам нужны новые отчёты, вы просто их пишете. Разные приложения могут одинаково обращаться к базе. Ограничения можно накладывать программно, чтобы они работали во всех приложениях.
Отойдя назад, вы увидите, что база данных – это большая структура данных, а приложения – наборы операций с ними. В сердце любого бизнес-приложения лежит большая функциональная база данных.
И тем не менее, мы хватаемся за объекты в приложениях. Простое следование моде? Или есть некая фундаментальная разница между тем, что нам нужно сделать в приложениях, и тем, что нам нужно сделать при работе с базой данных?
Ответ в том, что просто сделать через ООП, а что просто сделать в базах данных.
Хорошая ООП-архитектура позволяет легко менять то, как вещи связаны друг с другом. Инкапсуляция позволяет легко менять взаимодействие частей. Правда, в ООП не очень легко добавлять новые действия.
Но если у вас есть бизнес-процесс размещения заказа, который рефакторят на предмет поддержки новых бизнес-правил – тут ООП встаёт во всей красе. Те части кода, которым не нужно знать о происходящих изменениях, изолированы от тех, кому знать о них надо.
С другой стороны, хорошо разработанная база данных делает простым добавление новых запросов и операций. Возможно смотреть на данные с другой точки зрения или добавлять новые обновления данных. Клиентские приложения изолированы от таких вещей, как индексация и быстродействие.
Менять связи сложно. Если вы меняете структуру управления, и переходите от одного менеджера на отчёт к системе «многие ко многим», это сломает много приложений.
Поэтому, если мы запишем всё, что должно быть в бизнес-приложении, на карточках, те, что представляют длительные и редко изменяющиеся отношения, идут в базу данных, а те, что представляют эволюционирующие и изменяющиеся операции, идут в приложение.
Набор «карточек» (элементов приложения) обычно раза в четыре выше набора элементов базы данных. Всё меняется, бизнес должен учиться, расти и развиваться.
Так что насчёт ФП – код, написанный в функциональном стиле? Что насчёт простой организации ООП-программ в виде набора операций, действующих над относительно неизменными наборами данных?
Допустимо и то, и другое, однако всегда нужно задумываться над приоритетами – над продолжительностью связей. Если что-то вряд ли поменяется, при этом над этим будут работать разные меняющиеся вещи – его лучше оформлять в ФП-стиле. Если что-то меняется часто, это лучше оформить в виде ООП.
Если у каждого менеджера может быть несколько отчётов, а у каждого отчёта – только один менеджер, такие операции вряд ли стоит прятать за API, где объекты manager скрытым образом делегируют операции. Такую вещь проще создать в виде данных, над которыми производятся операции. Но правило насчёт стоимости доставки скорее всего поменяется, и его надо инкапсулировать посильнее, чтобы изолировать от него остальную часть программы.
Хорошие программы пишутся с помощью обоих стилей, потому что хорошие программы должны выполнять несколько разных задач.
- Программирование
- ООП
- Функциональное программирование
OO VS FP
Множество программистов на протяжении последних лет утверждают, что ООП и ФП — являются взаимоисключающими. С высоты башни из слоновой кости в облаках, ФП-небожители иногда поглядывают вниз на бедных наивных ООП-программистов и снисходят до надменных комментариев. Приверженцы ООП в свою очередь косо смотрят на «функционыльщиков», не понимая, зачем чесать левое ухо правой пяткой.
Эти точки зрения игнорируют саму суть ООП и ФП парадигм. Вставлю свои пять копеек.
ООП не про внутреннее состояние
Объекты (классы) – не структуры данных. Объекты могут использовать структуры данных, но их детали реализации скрыты. Вот почему существуют приватные члены классов. Извне вам доступны только методы (функции), поэтому объекты про поведение, а не состояние.
Использование объектов в качестве структур данных – признак плохого проектирования. Инструменты, вроде Hibernate называют себя ORM. Это некорректно. ORM не отображают реляционные данные на объекты. Они отображают реляционные данные на структуры данных. Эти структуры – не объекты. Объекты группируют поведение, а не данные.
Думаю, здесь дядя Боб ругает ORM за то они часто подталкивают к анемичной модели, а не к богатой.
Функциональные программы, как и объектно-ориентированные являются композицией функций преобразования данных. В ООП принято объединять данные и поведение. И что? Это действительно так важно? Есть огромная разница между f(o), o.f() и (f o) ? Что, вся разница в синтаксисе. Так в чем же настоящие различия между ООП и ФП? Что есть в ООП, чего нет в ФП и наоборот?
ФП навязывает дисциплину в присвоение (immutability)
В «тру фп» нет оператора присвоения. Термин «переменная» вообще не применим к функциональным ЯП, потому что однажды присвоив значение его нельзя изменить.
Да. Да. Апологеты ФП часто указывают на то что функции – объекты первого класса. В Smalltalk функции – тоже объекты первого класса. Smaltalk – объектно-ориентированный, а не функциональный язык.
Ключевое отличие не в этом, а в отсутствии удобного оператора присваивания. Значит ли это, в ФП вообще нет изменяемого состояния? Нет. В ФП языках есть всевозможные уловки, позволяющие работать с изменяемым состоянием. Однако, чтобы сделать это, вам придется совершить определенную церемонию. Изменение состояния выглядит сложным, громоздким и чужеродным в ФП. Это исключительная мера, к которой прибегают лишь изредка и неохотно.
ООП навязывает дисциплину в работе с указателями на функции
ООП предлагает полиморфизм в качестве замены указателей на функции. На низком уровне полиморфизм реализуется с помощью указателей. Объектно-ориентированные языки просто делают эту работу за вас. И это здорово, потому что работать с указателями на функции напрямую (как в C) неудобно: всей команде необходимо придерживаться сложных и неудобных соглашений и следовать им в каждом случае. Обычно, это просто не реалистично.
В Java все функции виртуальные. Это значит, что все функции в Java вызываются не напрямую, а с помощью указателей на функции.
Если вы хотите использовать полиморфизм в C вам придется работать с указателями вручную и это сложно. Хотите полиморфизм в Lisp: придется передавать функции в качестве аргументов самостоятельно (кстати, это называется паттерном стратегия). Но в объектно-ориентированных языках все это есть из коробки: бери и пользуйся.
Взаимоисключающие?
Являются две эти дисциплины взаимоисключающими? Может ли ЯП навязывать дисциплину в присваивании и при работе с указателями на функции. Конечно может! Эти вещи вообще не связаны. Эти парадигмы – не взаимоисключающие. Это значит, что можно писать объектно-ориентированные функциональные программы.
Это также значит, что принципы и паттерны ООП могут использоваться и в функциональных программах, если вы принимаете дисциплину «указателей на функции». Но зачем это «функциональщикам»? Какие новые преимущества это им даст? И что могут получить объектно-ориентированные программы от неизменяемости.
Преимущества полиморфизма
У полиморфизма всего одно преимущество, но оно значительно. Это инверсия исходного кода и рантайм-зависимостей.
В болшинстве систем когда одна функция вызывает другую, рантайм-зависимости и зависимости на уровне исходного кода однонаправленны. Вызывающий модуль зависит от вызываемого модуля. Но в случае полиморфизма вызывающий модуль все еще зависит от вызываемого в рантайме, но исходный код вызываемого модуля не зависит от исходного кода вызываемого модуля. Вместо этого оба модуля зависят от полиморфного интерфейса.
Эта инверсия позволяет вызываемого модулю вести себя как плагину. Действительно, плагины так и работают. Архитектура плагинов крайне надежна, потому что стабильные и важные бизнес-правила могут храниться отдельно от подверженных изменениям и не столь важных правил.
Таким образом, для надежности системы должны применять полиморфизм, чтобы создать значимые архитектурные границы.
Преимущества неизменяемости
Преимущества неизменяемых данных очевидны – вы не столкнетесь с проблемами одновременных обновлений, если вы никогда ничего не обновляете.
Так как большинство функциональных ЯП не предлагает удобного оператора присвоения, в таких программах нет значительных изменений внутреннего состояния. Мутации зарезервированы для специфических ситуаций. Секции, содержащие прямое изменение состояния, могут быть отделены от многопоточного доступа.
Итого, функциональные программы гораздо безопаснее в многопоточной и многопроцессорной средах.
Занудные философствования
Конечно приверженцы ООП и ФП будут против моего редукционистского анализа. Они будут настаивать на том, что существуют значительные философские, филологические и математические причины, почему их любимый стиль лучше другого. Моя реакция следующая: Пфффф! Все думают, что их подход лучше. И все ошибаются.
Так что там про принципы и паттерны?
Что вызвало у меня такое раздражение? Первые слайды намекают на то что все принципы и паттерны, разработанные нами за десятилетия работы применимы только для ООП. А в ФП все решается просто функциями.
Вау, и после этого вы что-то говорите про редукционизм? Идея проста. Принципы остаются неизменными, независимо от стиля программирования. Факт, что вы выбрали ЯП без удобного оператора присвоения, не значит, что вы можете игнорировать SRP или OCP, что эти принципы будут каким-то образом работать автоматически. Если паттерн «Стратегия» использует полиморфизм, это еще не значит, что он не может применяться в функциональном ЯП (например Clojure).
Итого, ООП работает, если вы знаете, как его готовить. Аналогично для ФП. Функциональные объектно-ориентированные программы – вообще отлично, если вы действительно понимаете, что это значит.
- Программирование
- Анализ и проектирование систем
- .NET
- Функциональное программирование
Функциональное программирование или ООП?
Часто встречаю статьи и доклады от функциональщиков, что функциональное программирование рулит, а объекты это треш. Не будем здесь говорить о процедурщиках, которые думают, что они функциональщики. Не будем их разочаровывать, что ни к кому из вышеперечисленных они порой не относятся (и по этой причине иногда идут лесом). Разберёмся, чем функциональное программирование отличается от других парадигм и для чего это всё вообще нужно.
Парадигмы придумывают людьми для каких-то специфических целей и для упрощения работы. Да-да, как я и сказал когда-то на форуме:
Архитектуру придумали для упрощения сложного кода, а не для усложнения лёгкого.
Какие же парадигмы придумали? На ассемблере мы пишем нечасто, поэтому в самый низ опускаться не будем. Лапшекод и последующий процедурный подход тоже, так как с ними всё понятно. Остановимся на высокоуровневых парадигмах, призванных структурировать этот лапшекод.
Объектно-ориентированный подход
Когда кода становится много, его нужно как-то разбить по процедурам. Когда процедур становится много, то их нужно как-то сгруппировать по обязанностям и разнести по модулям. Если несколько процедур и функций как-то связаны работой с одними и теми же данными, то их удобнее вместе с этими данными сгруппировать в объект.
Но если просто возьмёте груду кода и просто перенесёте процедуры в классы, как я говорил на итенсиве, то не станете сразу объектно-ориентированным программистом. Это другой подход к компоновке кода. Целый отдельный образ жизни и мыслей.
Настоящее ООП нацелено на разделение обязанностей и сокрытие информации.
Это парадигма, придуманная для моделирования объектов реального мира. Как она это делает? Удобно показывать на метафорах и аналогиях, поэтому рассмотрим ситуацию с тостером или микроволновкой:
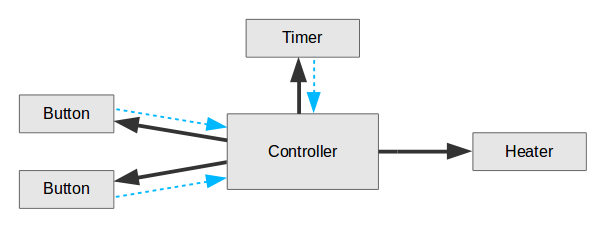
Есть контроллер, управляющий всеми запчастями чёрными стрелками и подписанный на состояние кнопок по голубым проводам. Как этот агрегат работает?
Кнопка включения передаёт сообщение Меня нажали . Контроллер передаёт сообщение Включись нагревателю и Запустись на 10 секунд таймеру, подписываясь при этом на его сигналы. Через указанное время таймер уведомляет Я истёк и контроллер передаёт Выключись печке. А по сигналу с кнопки выключения контроллер передаёт сигналы Выключись нагревателю и Стоп таймеру.
Если вдруг надо будет перепрограммировать логику, то всего лишь доработаем «прошивку» главного контроллера.
А если нужно добавить термометр, дисплей и GSM-модуль для отправки SMS-уведомлений? Запросто подключаем их к контроллеру своими «родными» разъёмами и в обработчике события истечения от таймера мы после остановки печки отправляем SMS о готовности. Или автоматически фотографируем обед и постим в Instagram. Но суть здесь одна:
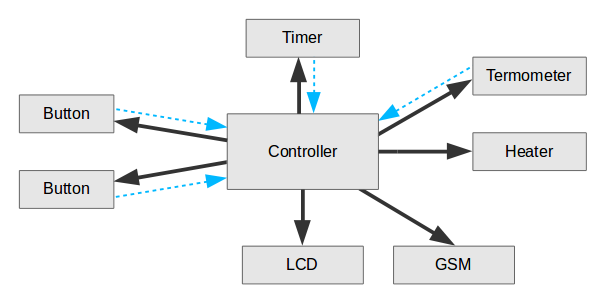
Контроллер при нажатии кнопки включает дисплей и подписывает его на события таймера через себя. Может и напрямую, но тогда дисплей и таймер должны быть совместимы. Что это напоминает?
Это классический подход Model-View-Controller (MVC), часто используемый в оконных приложениях, где есть много кнопок, дисплеев и прочих элементов.
В данном случае все связи идут не хаотически, а от контроллера. Нагреватель, таймер, дисплей и кнопки не знают друг о друге. Кнопки умеют только нажиматься, таймер только считать. Каждый делает только свою работу. Каждую специализированную запчасть легко проверить и поменять.
В такой системе можно вместо нагревателя даже поставить холодильник или шлагбаум. И у контроллера может быть возможность подключить что угодно:
class Controller < private $devices = []; function addDevice(ВклВыклInterface $device) < $this->devices[] = $device; > . >
лишь бы это «что угодно» поддерживало указанный интерфейс:
interface ВклВыклInterface
class Пылесос implements ВклВыклInterface < public function вкл() < . >public function выкл() < . >>
Тогда просто создаём все устройства и закидываем их в контроллер:
$controller->addDevice(new Шлагбаум()); $controller->addDevice(new Пылесос());
И такой контроллер будет всех их включать и отключать по таймеру.
В хозяйстве это вещь весьма полезная. Даже продвинутые варианты таких контроллеров уже есть:

В такой можно включить даже электропилу, реализующую интерфейс ЕвроВилкаInterface .
А что если у нас в хозяйстве появилась бензопила? Она заводится особым образом и имеет свои методы:
class Бензопила < public function включитьЗажигание() < . >public function открытьЗаслонку() < . >public function закрытьЗаслонку() < . >public function дёрнутьСтартер() < . >public function работает() < . >>
Если у бензопилы нет кнопок вкл и выкл как у электропилы, то просто напишем адаптер:
class БензопилаАдаптер implements ВклВыклInterface < private $пила; public function __construct(Бензопила $пила) < $this->пила = $пила; > public function вкл() < $пила = $this->пила; $пила->включитьЗажигание(); $пила->закрытьЗаслонку(); while (!$пила->работает()) < $пила->дёрнутьСтартер(); > $пила->открытьЗаслонку(); > public function выкл() < $this->пила->выключитьЗажигание(); > >
Он снаружи будет выглядеть так, как нужно нашему контроллеру, а внутри себя будет скрывать весь этот сложный процесс. Так можно и для ядерного реактора адаптер написать, если вдруг это понадобится.
В реальности нам пригодился бы скромный набор деталей:

И теперь одним махом включаем бензопилу в разъём контроллера:
$controller->addDevice(new БензопилаАдаптер(new Бензопила()));
Бензопила с Arduino-адаптером теперь ничем не отличается от нагревателя. Мощь полиморфизма 🙂
Всё как в жизни. Абстрагируясь от реализации всего этого, для нас каждый модуль это всего лишь ящик с парой проводов. Груда проводов и транзисторов в виде элементов открытого ассоциативного массива причинит много проблем, так как нечаянно можно замкнуть не тот провод. А закрытый толстым кожухом объект с парой видимых кнопок или разъёмов с этим справится идеально.
Приятно и удобно программировать специализированными ящиками, обменивающимися сообщениями.
Умело разделяя систему на объекты и продумывая сообщения между ними можно достичь нирваны в ООП. А влезая в это кривыми руками можно забыть о структуре и сделать месиво:
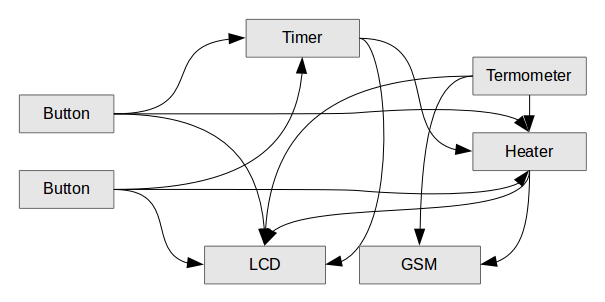
Здесь компоненты соединены кучами проводов и нужно всюду впаивать логику, чтобы термометр умел работать с дисплеем и включать печку. Бензопилу сюда уже так просто не включишь. Мы уже упоминали эту проблему при организации независимых модулей сайта с интересными картинками.
Функциональный подход
Если просто программируете процедурно и ещё не успели изучить хотя бы тот же ООП, то вы не обязательно получите функциональное программирование. ФП тоже о разделении обязанностей и тоже призвано структурировать лапшекод, но немного по-другому. Это так:
данные → функция1 → данные → функция2 → данные → функция3 → результат
Пример: если Вы есть в соцсетях, то вас постоянно парсят маркетологи:
Профили ВК → f1 → сообщества профилей → f2 → общие сообщества → f3 → число участников → f4 → сообщества больше 1000 → f5 → статистика сообществ → f6 → разбор по демографии → f7 → разбор по возрасту.
И получим результат:
[ 'male' => [ '18-24' => [ [ 'Id' => 123456, 'name' => 'Как купить Lamborghini студенту', 'population' => 152000, 'demography' => [ 'male' => 67, 'female' => 33 ], 'age' => [ '0-18' => 19, '18-24' => 23, '24-30' => 18, . ] ] ] ] ]
Можно добавить город вначале:
Город -> f1 -> Профили ВК -> f2 -> Сообщества -> .
и фильтры с группировками менять местами. Объекты с методами здесь никуда не впишешь.
Здесь вместо объектов, объединяющих данные с поведением, всё разнесено раздельно на сами данные и на их обработчики. Каждый обработчик представляет из себя функцию, принимающую исходные данные и возвращающую результат.
Здесь идеально подходят ассоциативные массивы и другие примитивные структуры. Они не нагружают оперативку и процессор созданием тысяч и миллионов объектов для каждого элемента. Но что если фильтраций будет много? Дабы не копировать миллионные массивы снова и снова, удобнее передавать все значения по ссылке. Или сделать структуры в виде классов с полями, чтобы все значения хранились в памяти в одном экземпляре и передавались по указателю.
Чем это отличается от обычного процедурного подхода?
Разбиение императивного кода на процедуры и функции в процедурной парадигме служит как инструмент абстракции в руках умелых или только для избавления от копипасты в руках обычных. Функции рассчитывают результат, а процедуры что-то куда-то записывают. Ведь нет смысла вызывать процедуру, которая ничего не возвращает и ничего при этом не делает.
В нашем парсере ничего записывать не надо и императивная пошаговость не нужна. Мы просто в потоке преобразуем одни данные в другие, не перезаписывая старые значения. Поэтому в функциональной парадигме можно выкинуть процедуры и переменные за ненадобностью и оставить лишь константы и функции.
Приятно и удобно работать с данными, прогоняя их через специализированные конвертеры.
Умело разделяя расчёты на данные и функции можно достичь нирваны в ФП. А влезая в это кривыми руками можно забыть о структуре и сделать месиво.
Но как на ФП пишут сайты?
Поток вычислений
Во-первых, не обязательно делать весь сайт на ФП. На сайте с логикой могут быть некие комбинированные расчёты, где ООП неудобен. Именно эти фрагменты можно реализовать функционально.
Например, нам нужно к товарам в корзине начислить скидку на один экземпляр каждого, которого заказали больше трёх. Вместо возни с циклами, методами и прочим низкоуровневым мусором мы просто определяем, какие фильтры и преобразователи нам нужны:
$countCondition = function (CartItem $item) return $item->getCount() > 3; >; $getDiscount = function (CartItem $item) return $item->getPrice() * 0.1: >;
и теперь просто прогоняем массив наших товаров $items поштучно через эти операторы:
$discount = array_sum( // суммируем array_map($getDiscount, // расчитанные скидки array_filter($items, $countCondition))) // отфильтрованных элементов
Если же работать с коллекциями вместо простых массивов, то можно реализовать и так:
$discount = $items ->filter($countCondition) ->map($getDiscount) ->sum();
Здесь у объектов класса CartItem скрипт считывает цену и количество. А как собирается результат? Потоком:
Товары -> фильтр() -> товары -> расчёт() -> скидки -> сумма() -> результат
По этому примеру придумал скринкаст о подсчёте скидок. За ним ещё будет о написании многопоточного парсера, показывающий пользу неизменяемых данных при распараллеливании процессов. Кто ещё не подписался на вебинары, тот, как обычно, будет в пролёте.
Работа сайта
Во-вторых, можно отследить нить исполнения самого сайта. Он выглядит как сложная функция от запроса:
GET, POST, FILES, SERVER → request() → router(request) → controller(request) → viewFile, viewData → render(. ) → response → send(response) → HTTP/1.1 200 OK
Теперь вызываем что-то вроде этого:
print_r(handle(request(GET, POST)))
и видим сгенерированный ответ в виде массива:
[ 'status' => [ 'code' => 200, 'message' => 'OK', ], 'headers' => [ 'Content-Type' => 'text/html', ], 'content' => '.