Децентрализация: Что это?
Децентрализация – это главное качество всех блокчейн-проектов, во многом именно благодаря децентрализации такие проекты набирают популярность и завоевывают доверие пользователей. Но что такое децентрализация? Какой проект называется децентрализованным, и в чем эта особенность выражается?
Итак, децентрализованным называется проект, в котором отсутствует третья сторона – администратор или руководитель, имеющий возможность единолично принимать решения и влиять на судьбу проекта. Также в децентрализованном проекте нет единого сервера, где хранится вся информация и, отключив который, можно закрыть проект, лишив пользователей возможности доступа к нему и вообще прекратив его существование. Тогда что же такое децентрализация? В неком общем смысле – это распределение. В децентрализованных проектах информация разбита на части и хранится на компьютерах всех пользователей сети. Это значит, что для того, чтобы повредить такую сеть нужно взломать более 51% пользователей, что в принципе невозможно. Если сказать другими словами, децентрализация представляет собой особенный процесс распределения власти, финансовых средств или определенных усилий. В такие действия не вмешивается глобальный управляющий орган. Это означает, что управление сетью совместно осуществляется множеством узлов сети, которые в равной степени разделяют обязанности и запускают одно и то же программное обеспечение узла. Информацию, хранящуюся в такой сети, нельзя подменить или исправить ведь она храниться сразу на множестве компьютеров, а на работоспособность системы нельзя повлиять какому-то отдельно взятому лицу.
Термин децентрализации часто связывают с термином блокчейн и не зря. Блокчейн — это децентрализованная база данных, которая хранит постоянно растущий список записей (блоков). Эти записи упорядочены в строгой последовательности, причем каждая последующая запись хранит часть информации о предыдущей записи. Такая база хранится на компьютерах пользователей (у нее нет единого сервера) и каждый, кто хранит базу — имеет ее полную копию и новые записи добавляются во все существующие копии.
Пока не очень понятно? Объясним на простом примере с яблоками:
· Саша купил 6 яблок
Записываем сей факт в блокчейн (некий дневник) и получаем блок №1. Рассылаем блок №1 Коле, Вите, Свете, Снежане и Маргарите (пользователям сети) – теперь все они знают, что у Саши 6 яблок.
· Саша отдает Коле 5 яблок, чтобы тот разделил им между своими друзьями.
Записываем и этот факт в блок №2. При этом блок №2 содержит уникальный идентификатор блока №1. Рассылаем этот блок Вите, Свете, Снежане и Маргарите.
· Коля отдает Вите 1 яблоко.
Записываем это в блок №3. Добавляем в запись уникальный идентификатор блока №2. Рассылаем блок всей сети.
· Коля отдает Свете 3 яблока чтобы та поделилась с подругами.
Записываем в блок №4. Добавляем идентификатор блока №3. Рассылаем всем блок.
· Света, вместо того, чтобы угостить яблоками подруг, съедает все 3 яблока и когда Снежана и Маргарита приходят к ней за обещанными яблоками (они ведь получили информацию о том, что, Коля передал Свете три яблока), Света пытается свалить вину на Колю – якобы, он дал ей всего 1 яблоко, а остальные оставил себе. Но запись в сети говорит о другом и Снежана и Маргарита прекрасно знают, что именно Света съела предназначавшиеся им фрукты.
Таким образом, децентрализация защищает нас от мошенничества внутри сети, делая транзакции предельно простыми и прозрачными и защищает сеть от взлома и влияния человеческого фактора.
Что представляет из себя децентрализованное хранение
Децентрализованное хранение данных представляет собой метод организации информации, при котором данные не хранятся на центральном сервере, а распределены по множеству независимых компьютеров, называемых узлами, которые соединены в одноранговую P2P сеть. Данные, загруженные в децентрализованную систему хранения, разбиваются на небольшие фрагменты и распределяются по нескольким нодам.
В децентрализованных сетях, таких как BitTorrent или IPFS, данные делятся на небольшие части, которые затем распределяются и сохраняются на различных узлах сети. Эти узлы могут быть компьютерами любых пользователей, подключенными к сети, что обеспечивает дополнительный уровень безопасности и устойчивости к сбоям. Поскольку данные хранятся на нескольких узлах одновременно, даже если один или несколько узлов выходят из строя или подвергаются атаке, информация остается доступной благодаря другим узлам, обладающим копиями данных.
Этот подход к хранению данных имеет несколько преимуществ:
- Устойчивость к сбоям: Если один или несколько узлов выходят из строя, данные остаются доступными благодаря другим узлам в сети.
- Безопасность: Децентрализованные сети используют шифрование и другие методы для обеспечения безопасности данных.
- Эффективность: Использование ресурсов узлов в сети происходит более эффективно, так как нагрузка распределяется между множеством участников.
- Приватность: Пользователи имеют больший контроль над своими данными, так как они не хранятся в одном центральном месте, которое может быть подвергнуто взлому или слежке.
- Надежность: Децентрализованные системы могут быть более надежными, так как они не зависят от одного узла или организации.
Однако несмотря на преимущества децентрализованного хранения данных, у этого метода есть свои недостатки:
- Доступ к информации в децентрализованных системах может занимать больше времени из-за зависимости от сети узлов.
- Также децентрализованные системы уязвимы перед вредоносными узлами, что может угрожать безопасности данных.
- Перебои в сетевой инфраструктуре могут также повлиять на доступность данных.
- Стандартизация в децентрализованных системах отсутствует, что затрудняет совместимость между разными протоколами, и риски, связанные с шифрованием и управлением ключами, до сих пор не полностью решены.
Больше материалов у нас в Telegram ��
Децентрализованные облачные вычисления — благо или зло?
В данной статье рассмотрим незаслуженно забытую тему децентрализованных облачных вычислений, проведём анализ существующих решений и попробуем ответить на главный вопрос — почему мастодонты AWS / Azure до сих пор остаются единственным production-ready решением для облачных вычислений, не оставляя шансов децентрализованным пулам мощностей?
Определение и область применения
Начнём с области применения. Облачные вычисления применяются для широкого спектра задач:
- Работа backend’a и хостинг веб-сайтов, мобильных и десктопных приложений
- Обучение и инференс нейронных сетей, проведение computing-heavy вычислений для исследовательских задач в различных областях
- Облачный гейминг, рендеринг
- И множество других требовательных к вычислительной мощности задач
Вариантов их решения условно два: покупка и содержание собственного сервера, либо обращение к услугам облачных провайдеров. Второй вариант имеет множество плюсов: произвольная локация сервера, набор различных конфигураций, техническая поддержка, гарантии стабильной работы.
Минусы тоже есть: высокая цена, тонкая настройка конфигурации невозможна — можно попасть в промежуток между дешевыми, но недостаточными, и дорогими, но избыточными конфигурациями, самый актуальный — для граждан и бизнеса стран, находящихся под санкциями, вариант зарубежных облачных провайдеров сопряжен с рисками и головной болью с оплатой.
А что же децентрализованные вычисления? Это тот же AWS, только машины расположены не в множестве централизованных серверных в ряде регионов мира, а в домах / гаражах / серверных множества людей по всему земному шару, а каждая машина / кластер будет являться нодой сети блокчейна. Гарантом сделки будет выступать не централизованная корпорация, а смарт контракты, платим не картой, а токенами сети.
Плюсы и минусы этого подхода ниже.
Польза и вред
В децентрализованных вычислениях может принимать участие практически любое устройство: старый компьютер на пентиуме, мобильный телефон, майнинг ферма, любительский GPU кластер, современный домашний ПК. А расположены они могут быть в любом месте с электричеством и интернетом.
Это предоставляет арендаторам вычислительных мощностей феерический выбор конфигураций и локаций — можно арендовать мощности престарелого ПК слесаря дяди Васи, а можно арендовать рендер ферму дядюшки Джона из Северной Америки.
Ограничить вам доступ к вычислениям никакие санкции, ограничения и запреты не смогут — блокчейн живет своей жизнью.
Привлекательна и потенциальная стоимость таких услуг — косты и желаемая маржа частных энтузиастов арендодателей мощностей в разы ниже, чем у корпоративных серверов.
Распределенные системы потенциально могут решить задачу скейлинга мощностей «чем больше – тем быстрее» гораздо эффективнее централизованных провайдеров. Множество различных нод в распределенной сети для подобных задач могут сработать эффективнее реплицированных серверных инстансов, к примеру, в AWS.
Сказка, не правда ли? Но чудес не бывает, поэтому без минусов не обошлось.
У дяди Васи отключили электричество / интернет, и ваши вычисления улетели коту под хвост. Сэкономили? Да. Рады? Маловероятно.
Облачные провайдеры обладают необходимой инфраструктурой для обеспечения бесперебойной работы ваших вычислений, а вот нода из децентрализованной сети — очень вряд ли.
Ваши данные и алгоритмы представляют коммерческую ценность? Дядюшка Джон может оказаться любопытным. Возможно он захочет посмотреть, что же вы крутите на его ноде. И ваши данные / алгоритмы будут скомпрометированы.
К мастодонтам AWS и Azure в этом плане доверия, конечно же, в разы больше.
Посмотрим, что из существующих решений нам сейчас доступно.
Актуальные децентрализованные решения для вычислений и хранения данных
Начнем с периферии.
Вычисления, как правило, берутся не из воздуха, а производятся на основе данных, которые где-то хранятся. Порой эти данные могут иметь очень внушительный размер. Какие есть решения децентрализованного хранения данных?
IPFS (InterPlanetary File System) — технология распределенной файловой системы, основанная на DHT (Distributed Hash Table) и протоколе BitTorrent. Она позволяет объединить файловые системы на различных устройствах в одну, используя контентную адресацию.
Обладает высокой пропускной способностью, хранение бесплатно. Однако удаление файлов не предусмотрено, да и вообще хранение файла в сети кем-то, помимо автора, не гарантированно. Оплата для хостеров не предусмотрена.
Есть альтернативные технологии, хранение в которых не бесплатно.
Например, Sia, Storj, Ethereum Swarm, MadeSAFE.
Чтобы обеспечить надежность хранения, используются различные проверки, например, proof of storage (доказательство принятия файла), proof of retrievability (доказательство, что файл в наличии и может быть извлечен). Пользователь платит за хранение, а хостеры получают награду. Плюсы — хранение файлов гарантированно, их можно удалять, пропускная способность высока, надежность хранения засчёт финансовой мотивации. Минусы — не бесплатно и, как правило, совсем не дешево.
С хранением понятно, а что же вычисления?
Единственный относительно известный и развивающийся сервис, найденный мной — iExec.
Схема работы от авторов представлена на рисунке.
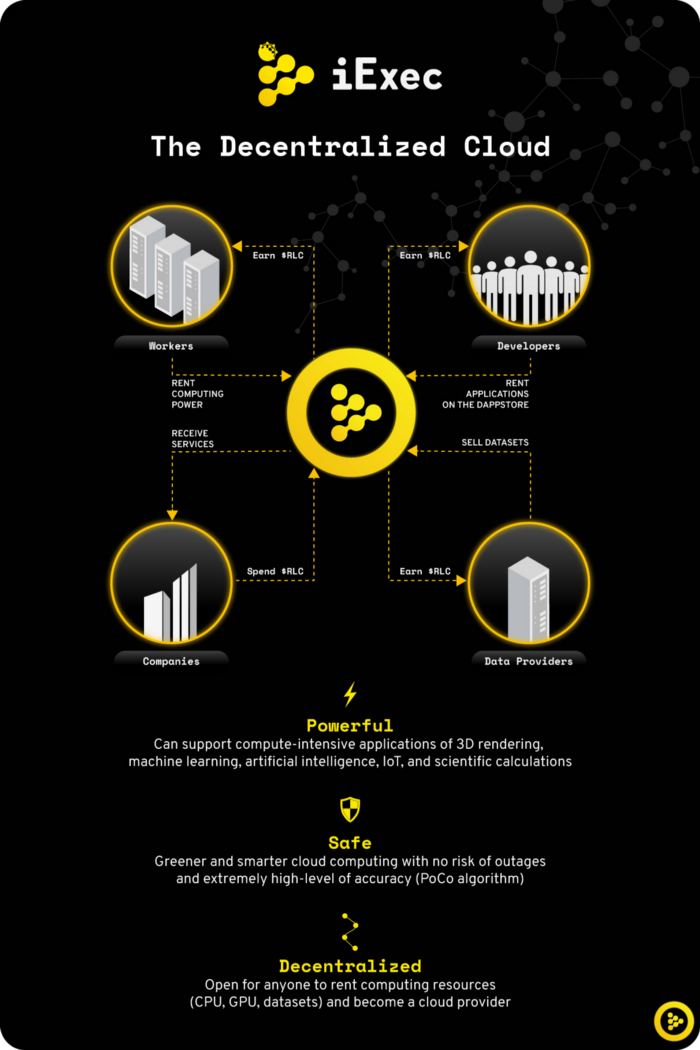
На бумаге все выглядит крайне пристойно: децентрализация, безопасность данных, выбор конфигурации и локации, прозрачность взаимодействия хостер / арендатор. Внутренняя валюта — токен RLC, используемый для оплаты и вознаграждения хостеров.
А что же на деле?
А на деле есть нюанс — для нейросетей и других «обычных» вычислений это решение не подойдет. Только dApps, только Web 3.0. Но сервис вполне рабочий — в пуле есть мощности для аренды, их даже кто-то арендует и что-то с ними делает.
Узкоспециализированная, конечно, но вполне жизнеспособная (и живущая) система.
А где же провайдеры децентрализованных «обычных» вычислений?
Досконально прошерстив гугл могу со всей ответственностью заявить — ready-to-go решений в этой области мной обнаружено не было. Проекты на бумаге, замороженные, концепты и гипотетические проекты есть, но когда они попадут в реальную жизнь и попадут ли — большая загадка.
Заключение
Что мы получаем в сухом остатке?
Распределённый реестр, он же блокчейн, выглядит применимым к задаче облачных вычислений. Децентрализованные облачные вычисления имеют право на существование и точно могут найти своих потребителей, но с текущими проблемами (которые довольно сложно решить) шансы на конец гегемонии AWS и др. облачных решений крайне малы.
Недостаточно спроса (по причине рисков и проблем), недостаточно предложений — ведь их рождает спрос. Не будут же хостеры просто так включать свои машины в сеть вычислений, если в ней никто особенно и не вычисляет. Выстреливших проектов не наблюдается, развития и обсуждения темы — тоже.
С хранением файлов всё несколько более радужно. Инфраструктура есть, решений немало, спрос есть как минимум со стороны dApps — не будет же децентрализованное приложение хранить данные на централизованном файлохранилище.
И не будем забывать — в стезе децентрализованного хранения и обмена файлами есть крайне успешный мастодонт uTorrent 🙂
От себя добавлю, что мне, как ML ресёрчеру, было бы очень интересно воспользоваться децентрализованной сетью GPU кластеров для обучения нейросетевых моделей, если бы такое решение существовало. Но увы и ах — пока это невозможно.
Будем наблюдать за развитием этой отрасли.
- Блокчейн
- децентрализация
- децентрализованные сети
- децентрализованные платформы
- облачные вычисления
Децентрализованное будущее. Каждому человеку — безопасная капсула для личных данных
В 2009 году, когда самым продвинутым браузером в мире считалась Opera, разработчики выкатили уникальную функцию Opera Unite, что-то вроде интегрированного веб-сервера. Со своей маршрутизацией, схемой именования ресурсов и прокси — всё внутри экосистемы из одноранговой сети пользователей. Грубо говоря, каждый пользователь Opera становился хостером — и раздавал статические ресурсы.
В 2012 году проект Opera Unite закрыли. Ребята примерно на десять лет опередили время…
Если бы такая схема стала мейнстримом, мы бы сегодня жили в другом мире. Возможно, не случилось бы засилья централизованных платформ, которые зафиксировали у себя пользовательский контент — и раздают его через свою сеть серверов.
Сегодня всё чаще возникают идеи «демонтировать» эти огороженные сады, то есть централизованные корпорации. Вернуться к справедливому распределению власти в интернете, как это изначально было задумано в пиринговых системах. Каждый пользователь должен владеть своими файлами в прямом и переносном смысле.
Именно такую цель поставили перед собой разработчики нового проекта Schluss.

Идея Schluss
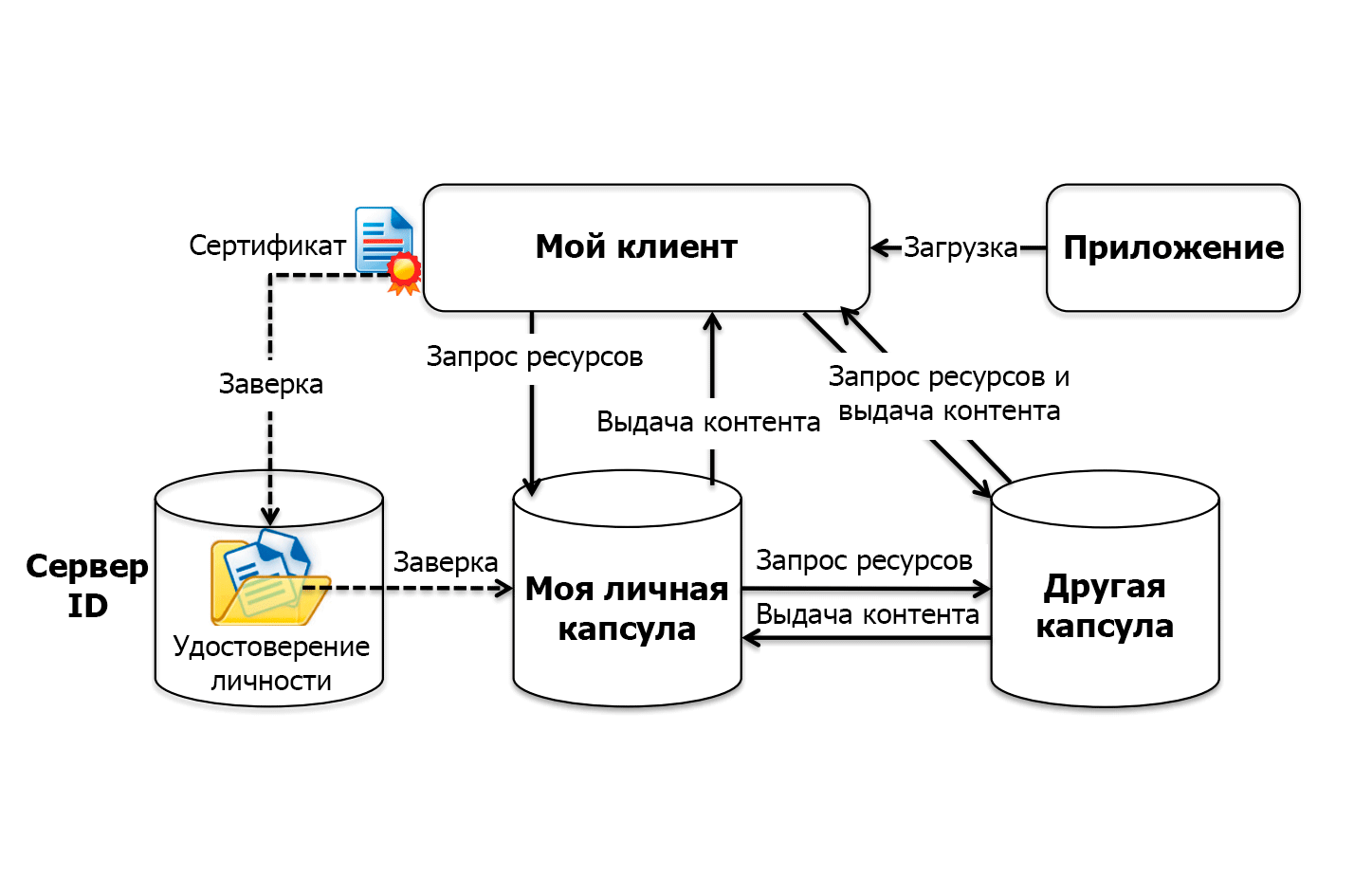
Основная идея Schluss — каждый человек сам хранит собственные данные в своём безопасном хранилище. Он может поделиться какой-то личной информацией, отвечая на запросы от других узлов или программных модулей. Все разрешения чётко настраиваются.
1. Сделать копию информации
2019 год. Этот пункт можно считать выполненным, поскольку большинство операторов типа Facebook, Google и «Яндекса» сейчас позволяют сделать копию своих данных, например, в виде PDF-файла. Однако сами данные по-прежнему хранятся на их серверах.
2. Разработка хранилища
2023 год. Разработка защищённого криптохранилища Schluss, доступ к которому есть только у владельца. Загрузка туда копии личных данных.
Ваша информация по-прежнему хранится у самих организаций, таких как банк, государственные органы, школы и больницы. Только вы решаете, с кем разрешено делиться этой информацией. Например, разрешаете своему врачу передать часть медицинской информации фармацевту. Настройки разрешений — прямо в хранилище Schluss, через мобильное приложение. Такой подход обеспечивает синхронизацию, потому что каждый раз, когда врач изменяет какую-то часть информации, данные у фармацевта также автоматически обновляются.
3. У вас — единственная копия
Ни одна организация больше не хранит ваши данные, все они сразу поступают к вам и выдаются строго по разрешениям. Если какая-то организация (банк, работодатель, рекламное агентство) хочет получить информацию о вашем адресе, номере телефона или зарплате, вам поступает запрос. В нём объясняется, что она хочет знать и с какой целью. Затем вы даёте разрешение на раскрытие информации. Или нет.

Внешние приложения могут использовать эту информацию для обеспечения коммуникации между личными капсулами отдельных пользователей. Как вариант, «капсулы» могут коммуницировать между собой напрямую по пиринговой схеме.
Сообщество Schluss призывает всех желающих присоединиться к разработке.
Концепция в чём-то похожа на проект Solid от Тима Бернерса-Ли (2018 год).
Как развивается Solid?
Согласно идеологии Solid, основной метод, который позволяет вернуть людям контроль над информацией — это отделение хранения данных от иных сервисов. Из программной статьи:
Это означает, что люди могут хранить свои данные, где хотят, в то же время пользуясь любыми сервисами. Для хранения своих текстов, фотографий и видео мы можем выбрать любого провайдера — или просто хранить их на собственном компьютере. Любая сторонняя служба с нашего разрешения пользуется этими данными, независимо от места хранения. Хранилище может осуществлять услугу аутентификации.
Такая логика порождает концепцию модуля персональных данных (personal data pod), в которой мы храним всю созданную информацию. Даже тривиальная часть данных вроде поставленного лайка, хранится в нашем приватном модуле.
Хотя подобная степень децентрализации может показаться экстремальной, вспомните, что лайки раскрывают глубоко личную информацию, поэтому есть смысл поставить их под контроль.
Это полное владение данными обеспечивает очень детальный контроль доступа: пользователи могут выборочно предоставлять друзьям или приложениям разрешения на чтение или запись определённых фрагментов. Например, публиковать ли свою фотографию и полное имя, кто увидит лайки и комментарии, какие приложения будут редактировать фотографии и посты. В любой момент разрешение можно изменить или отозвать.
Допускается несколько модулей данных для различных целей: например, модуль для личных и семейных фотографий, модуль с правилами хранения профессиональных данных для работы, университетский модуль с учебными материалами и оценками.
После регистрации на одном из solid-серверов пользователь получает идентификатор и личный «контейнер» (solid pod). Как вариант, можно поднять локальный сервер (см. инструкцию по установке). После создания модуля человек решает, какие данные и где хранить.

За прошедшие годы на базе Solid уже созданы десятки приложений.
Движение в этом направлении идёт со всех сторон.
Децентрализованный идентификатор: Web5 и DID
Известный биткоин-энтузиаст и предприниматель Джек Дорси недавно объявил о создании платформы Web5. Это разработка TBD (филиал известной платёжной системы Block).
С точки зрения семантики название Web5 символизирует сумму существующих технологий:
Web2 + Web3 = Web5
Но на самом деле технология, которая лежит в основе Web5, уже давно существует. Никто её просто так не называл.
Но сейчас с лёгкой руки Джека Дорси можно предположить, что новое название прилипнет. Впрочем, название не принципиально. Главное, что люди обратят внимание на фундаментальные сущности предлагаемой архитектуры:
- децентрализованная идентификация,
- децентрализованные веб-узлы.

Архитектура «клиент-сервер» проста и даёт людям доступ к программному обеспечению без поддержания собственной инфраструктуры. Однако эта простота имеет свои недостатки как для пользователей, так и для поставщиков программного обеспечения.
Первый недостаток — отсутствие переносимости данных. В архитектуре «клиент-сервер» каждое приложение — это информационный бункер. Если у человека десять различных приложений, у него десять различных представлений своей личности. Он вынужден хранить информацию о своей учётной записи в десяти разных местах. Это неудобно и сайтам (провайдерам): все они вынуждены с нуля выстраивать репутацию человека, хотя тот может быть уже достаточно известен на других платформах, которыми пользуется.
Второй недостаток — отсутствие конфиденциальности. Поскольку все данные хранятся на сервере, пользователь не контролирует, как используется его личная информация.
Web3 частично решает первую проблему, но не вторую. Публичный блокчейн используется как своего рода глобальный слой для хранения информации, чтобы переносить свои данные из одного приложения в другое. Просто подключаем кошелёк Metamask, и готово. Мой кошелёк — моя личность.
Web5 выводит децентрализацию на новый уровень. Здесь у человека тоже есть личный кошелёк, но он хранит не только криптографические ключи, но и другие документы, которые могут понадобиться в повседневной жизни (удостоверения, паспорта, абонементы, дисконтные карты и др.).
То есть это словно безопасная капсула для личных данных, которая хранится у самого человека.

Такой подход решает проблему переносимости данных с самого начала. Если пользователи сами хранят мастер-копию своих данных, то нет необходимости их обновлять в блокчейне или где-то ещё.
Но физическое владение своими данными — это самое простое. Сложнее — обеспечить работу множества приложений в новой парадигме, сохранив удобство на уровне web2 и web3. Для этого нужно гарантировать целостность данных и обеспечить удобную коммуникацию.
Пионеры web5 в течение последних лет трудились над решением этих проблем. И сейчас разработан ряд технических стандартов, библиотек и коммерческих продуктов, доступных разработчикам. Хотя ещё слишком рано говорить о том, какие именно технологии в итоге получат распространение.
Технический директор Firefox Эрик Рескорла (Eric Rescorla) в недавней статье рассуждает об основных концепциях Web5 — распределённых веб-узлах (DWN), распределённых веб-приложениях (DWA), децентрализованных идентификаторах (DID) и прочих понятиях.

Он говорит, что нам предстоит трудная задача определения протоколов, специфичных для конкретной области, поверх более универсального каркаса Web5.
Неизвестно, когда это случится, и случится ли вообще. Но работа по воплощению в жизнь уже ведётся.
Демо web5
- Animo
- Несколько демо от провинции Британская Колумбия
- Более техническое демо, как запустить децентрализованные агенты идентификации у себя в консоли и заставить их соединяться и общаться друг с другом через DIDComm.
Стандарты и спецификации web5
- Децентрализованные идентификаторы (DID). Стандарт W3C
- Проверяемые документы (Verifiable Credentials, VC). Стандарт W3C для «верифицируемых учётных данных», основополагающего примитива для криптографических доказательств о владельце DID.
- DIDComm. Протокол безопасной коммуникации между владельцами DID и обмена информацией между агентами.
- Децентрализованные веб-узлы (DWN). Спецификация веб-службы, которая может действовать от имени отдельных пользователей или других владельцев DID. Позволяет разрабатывать конечные точки, которые принимают запросы от имени пользователя, контролирующего DWN.
- Проверяемый идентификатор юридического лица (vLEI). Фреймворк для уникальной идентификации юрлиц и их представителей.
Опенсорсные проекты web5
- ACA-Py. Реализация облачного агента, основанная на спецификации Hyperledger Aries. Действует от имени одного или нескольких держателей DID для отправки и получения сообщений и учётных данных с помощью DIDComm.
- dwn-sdk-js. Частичная реализация DWN от TBD.
- Veramo. JS-инструменты для создания приложений с децентрализованной идентификацией и верифицируемыми учётными данными.
- Ion. Биткоин-совместимая cеть второго уровня (Level 2) специально для закрепления информации DID в блокчейне. Реализует протокол Sidetree, который не завязан строго на Bitcoin.
… где did означает схему, example представляет метод DID, а — 123456789abcdefghi — идентификатор для этого конкретного метода.
Метод описывает, как использовать идентификатор для поиска так называемого документа DID. А он содержит фактическую информацию об идентификации, например, в структуре JSON-LD:
В июле 2022 года консорциум W3C отклонил возражения Google и Mozilla и утвердил окончательную схему DID. Google и Mozilla предлагали конкретно описать в спецификациях формат методов DID. Но консорциум отклонил это предложение.
Mozilla, в свою очередь, заявила, что с более чем сотней существующих методов без контроля и совместимости между ними спецификации DID фундаментально неполноценные, и поэтому их нельзя принимать в качестве рекомендаций W3C.
Так или иначе, но процесс принятия спецификаций DID, DWN, dWeb и Web5 уже запущен. Пока не совсем ясно, какую форму он примет. Ясно только направление, в котором двигаются технологии — это децентрализация сервисов и максимальный контроль людей над своей личной информацией. В целом, это соответствует трём главным задачам, которые Тим Бернерс-Ли сформулировал ещё в 2017 году:
- вернуть контроль над нашими персональными данными,
- предотвратить распространение дезинформации,
- обеспечить прозрачность политической рекламы.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS .