��Как снизить нагрузку на Hive OS и улучшить производительность
Будьте внимательны при завершении процессов или перезагрузке системы, чтобы не потерять важные данные. Всегда делайте резервные копии перед внесением любых изменений в свою систему.
Детальный ответ
Как снизить задержку в Hive OS
Задержка (или «ла») в Hive OS может быть вызвана различными факторами, такими как неполадки сетевого соединения, неоптимальные настройки майнинговых программ и недостаточные ресурсы компьютера. В этой статье мы рассмотрим несколько способов снижения задержки в Hive OS.
1. Проверьте соединение с интернетом
Неполадки сетевого соединения могут быть одной из причин задержки в Hive OS. Проверьте подключение к интернету и убедитесь, что ваше соединение стабильно и надежно. Вы можете выполнить следующую команду в терминале Hive OS, чтобы проверить связь с серверами:
ping google.comЕсли вы получаете большое количество потерянных пакетов или высокую задержку, возможно, вам следует обратиться к вашему интернет-провайдеру для улучшения соединения.
2. Оптимизируйте настройки майнинговых программ
Настройки майнинговых программ могут влиять на задержку в Hive OS. Возможно, вы можете изменить некоторые параметры для улучшения производительности и снижения задержки. Например, вы можете изменить количество одновременно выполняемых потоков или использовать оптимизированные алгоритмы майнинга. Варианты настроек могут зависеть от используемой вами майнинговой программы.
Вот пример простой команды для изменения количества потоков в Claymore’s Dual Ethereum Miner:
-etha 0/1/2/3/4/5Здесь значение «0» означает автоматическое определение количества потоков, а значения от «1» до «5» соответствуют количеству ядер вашего процессора. Экспериментируйте с разными значениями, чтобы найти оптимальное для вашей системы.
3. Увеличьте ресурсы компьютера
Недостаточные ресурсы компьютера, такие как оперативная память или процессор, могут также вызывать задержку в Hive OS. Убедитесь, что ваш компьютер имеет достаточно ресурсов для выполнения майнинга. Если у вас недостаточно оперативной памяти, вы можете попробовать увеличить ее объем или закрыть ненужные приложения, чтобы освободить ресурсы для майнинга.
Вот пример команды для отображения информации о состоянии памяти в Hive OS:
free -hВы увидите общий объем доступной и использованной памяти. Если вы видите, что доступной памяти недостаточно, возможно, вам следует увеличить объем оперативной памяти в вашей системе.
4. Обновите Hive OS и майнинговые программы
Некоторые задержки могут быть вызваны ошибками или устаревшими версиями Hive OS или майнинговых программ. Убедитесь, что у вас установлена последняя версия Hive OS и вашего выбранного майнингового программного обеспечения. Вы можете использовать следующую команду для обновления Hive OS:
hive-replace -yДля обновления майнинговых программ, вы можете посетить официальные веб-сайты разработчиков программ и загрузить последние доступные версии.
5. Проверьте оборудование на предмет повреждений
Задержка в Hive OS также может быть вызвана поврежденным оборудованием, таким как неисправная видеокарта или блок питания. Проверьте ваше оборудование на наличие повреждений и убедитесь, что оно работает должным образом. Вы можете выполнить диагностику оборудования с помощью специальных инструментов, таких как FurMark для проверки видеокарты.
Если вы обнаружите повреждения оборудования, вам может потребоваться заменить его или обратиться к специалисту по ремонту.
6. Поддержка Hive OS
Если вы все еще испытываете задержку в Hive OS после применения вышеперечисленных рекомендаций, вы можете обратиться в поддержку Hive OS для получения дальнейшей помощи. Они могут предложить индивидуальное решение проблемы, которая может быть связана с вашей конкретной системой.
Надеюсь, эти советы помогут вам снизить задержку в Hive OS и улучшить производительность вашего майнинга. Удачи в вашем майнинговом пути!
Что такое LA в Hive OS: основные принципы и функции
La в Hive OS — это функция, которая используется для вычисления лага (задержки) в данных. Она позволяет вычислить разницу между значением в текущей строке и значением на предыдущей строке в указанной колонке данных. Эта функция часто используется для анализа последовательных значений и определения времени между ними. Пример использования функции La в Hive OS:
SELECT value, LAG(value) OVER (ORDER BY timestamp) AS lag_value FROM my_table;
В этом примере мы выбираем значение и применяем функцию LAG к столбцу value в таблице my_table. Функция LAG вычисляет задержку между текущим значением и предыдущим значением в столбце value, упорядоченном по столбцу timestamp. Надеюсь, это помогло вам понять, что такое La в Hive OS.
Детальный ответ
Что такое LA в Hive OS?
LA в Hive OS относится к показателю нагрузки процессора (Load Average). Это число отображает среднюю нагрузку на процессор сервера за определенный период времени. В основном, LA отображает, сколько работающих процессов в данный момент времени требует процессора для выполнения своей работы. Познакомимся с понятием нагрузки процессора, и далее рассмотрим, как LA используется в Hive OS и как его интерпретировать.
Нагрузка процессора
Нагрузка процессора — это количество работы, которую процессор выполняет в определенный период времени. Это может быть мера количества процессов, которые процессор выполняет одновременно, или количество процессорного времени, затраченного на выполнение задач. Нагрузка процессора измеряется в виде среднего числа задач, выполняемых процессором за конкретный период времени. Чем выше значение нагрузки, тем больше процессор выполняет задач в единицу времени.
LA в Hive OS
LA в Hive OS представлено в виде трех чисел, разделенных запятой, которые указывают на нагрузку процессоров в определенные интервалы времени. Например, значение «0.45, 0.52, 0.60» означает, что в последний 1, 5 и 15 минут нагрузка на процессор была соответственно 0.45, 0.52 и 0.60. LA в Hive OS обновляется каждые 5 секунд, чтобы предоставлять актуальную информацию о нагрузке на сервер. Значения LA могут помочь вам оценить, насколько захвачен ваш процессор работой и насколько эффективно он выполняет работу в данный момент времени.
Как интерпретировать LA?
- 0.00-0.70: Низкая нагрузка
- 0.70-1.00: Нормальная нагрузка
- 1.00-2.00: Повышенная нагрузка, но всё ещё приемлемая
- 2.00-4.00: Высокая нагрузка, требуется внимание
- Более 4.00: Критически высокая нагрузка, необходимо принять меры
Пример использования LA в Hive OS
В Hive OS вы можете использовать информацию о нагрузке процессора для принятия различных решений. Например, если вы видите резкий рост нагрузки процессора, вы можете проверить, какие приложения или процессы вызывают эту увеличенную нагрузку и предпринять меры по оптимизации или устранению нагрузки.
Вы также можете использовать значения LA вместе с другими статистическими данными, чтобы понять, какая нагрузка выполняется в целом. Например, вы можете сравнить значения LA с использованием потребляемого процессорного времени, чтобы определить, какие процессы занимают большую долю ресурсов и как это можно оптимизировать.
Вот пример использования команды «top» в Hive OS для просмотра LA:
Команда «top» отображает текущую нагрузку и статистику процессора. В строке, начинающейся с «load average», вы можете найти значение LA.
Заключение
LA (Load Average) в Hive OS является важным показателем для измерения нагрузки на процессор вашего сервера. Понимая, как интерпретировать значения LA, вы можете оптимизировать работу вашей системы и обеспечить ее эффективность. Учтите эти советы и используйте информацию о нагрузке процессора для принятия решений по оптимизации и улучшению производительности вашего сервера в Hive OS.
�� Как уменьшить потребление энергии в Hive OS в десять раз ��
Если вы хотите уменьшить размер LA (logical address space) в Hive OS, вы можете использовать команду ALTER TABLE для изменения параметров таблицы. Вот пример:
-- Изменение параметра LA таблицы ALTER TABLE table_name SET TBLPROPERTIES ('hive.io.heap.size'='small');
Вы можете заменить ‘table_name’ на имя вашей таблицы. Эта команда устанавливает значение «small» для параметра ‘hive.io.heap.size’, что приводит к уменьшению размера LA. Обратите внимание, что изменение размера LA может повлиять на производительность запросов. Убедитесь, что вы понимаете последствия этого изменения перед его применением. Рекомендуется также выполнить резервное копирование данных перед изменением параметров таблицы.
Детальный ответ
- Используйте индексы для ускорения поиска данных.
- Ограничьте количество возвращаемых строк запросом с использованием предложений LIMIT и OFFSET.
- Избегайте выполнения ненужных соединений таблиц, если это возможно.
- Используйте агрегатные функции, чтобы сгруппировать данные и уменьшить количество строк.
-- Пример использования индексов CREATE INDEX index_name ON table_name (column_name);⚙️ 2. Настройка параметров Hive
Настройка некоторых параметров Hive также может помочь уменьшить LA:
- Увеличьте размер памяти для выполнения запросов, установив параметр hive.cbo.enable=false.
- Увеличьте количество параллельных задач, установив параметр mapreduce.job.running.map.limit.
- Оптимизируйте план выполнения запросов с помощью параметра hive.optimize.reducededuplication.
-- Пример изменения параметра Hive SET hive.cbo.enable=false;�� 3. Оптимизация конфигурации системы
Для уменьшения LA в Hive OS также можно оптимизировать конфигурацию системы:
- Добавьте больше памяти для сервера Hive.
- Увеличьте количество ядер процессора, доступных для Hive.
- Разделите задачи на несколько узлов, чтобы увеличить параллелизм.
- Оптимизируйте настройки хранения данных на диске.
�� 4. Анализ и оптимизация производительности
Инструменты анализа производительности могут помочь вам идентифицировать проблемные запросы и производительность системы в целом. Рассмотрим некоторые из таких инструментов:
- Explain Plan: Позволяет узнать план выполнения запроса и определить узкие места.
- Hive Web UI: Веб-интерфейс, позволяющий отслеживать статистику и производительность запросов.
- Анализатор профиля запроса Hive: Помогает определить, где тратится больше всего времени при выполнении запросов.
С помощью этих инструментов вы сможете выявить проблемные места и принять меры по их оптимизации.
�� 5. Регулярное обслуживание и мониторинг
Регулярное обслуживание и мониторинг вашей системы Hive помогут предотвратить проблемы с производительностью и уменьшить LA. Вот некоторые меры, которые можно предпринять:
- Очистка и компактация таблиц, чтобы уменьшить размер данных.
- Мониторинг загрузки с помощью инструментов мониторинга производительности, таких как Grafana или Ambari.
- Анализ журналов и лог-файлов для выявления проблем и ошибок.
- Регулярное резервное копирование данных для предотвращения потери информации.
Путем регулярного обслуживания и мониторинга вы сможете предотвратить большинство проблем и поддерживать систему в оптимальном состоянии.
В завершение статьи хочу добавить, что уменьшение LA в Hive OS требует систематического подхода и комбинации различных методов оптимизации. Используйте описанные выше рекомендации и инструменты для достижения максимальной производительности вашей системы Hive.
GPU FAQ
The farm is constantly rebooting. If I turn logs-on via Hive Shell, what should I pay attention to?
Pay attention to the log lines that appear right before the rig goes offline. Apart from this, you can launch this command via Hive Shell: tail -f /var/log/syslog (you can interrupt the command by pressing the keys Ctrl-C).
When the rig goes offline, Hive Shell will disconnect, and you will see the required lines on the screen.
How to reduce the GPU power consumption?
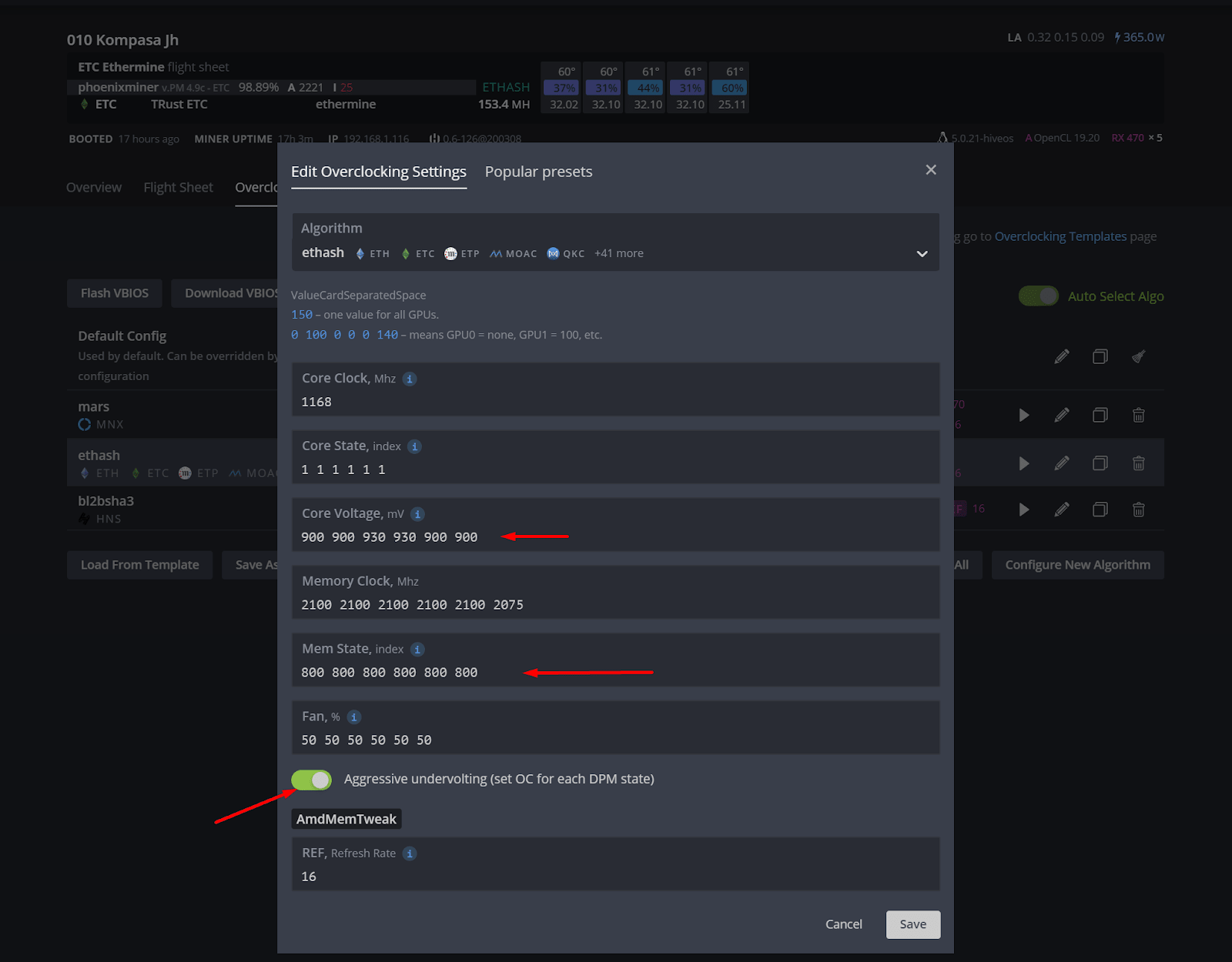
To reduce the consumption of your GPUs (when using Hiveon OS), you can specify the parameters of the core voltage and memory individually for each card.
To do this, go to the Overclocking section on your worker and specify the necessary values in the overclocking profile. Please note that in the Memory Status column you can indicate both the status index 0, 1, or 2, and the voltage in mW.
Also, to reduce power consumption, you can use the aggressive undervolting mode:
How to check internet on GPU rig?
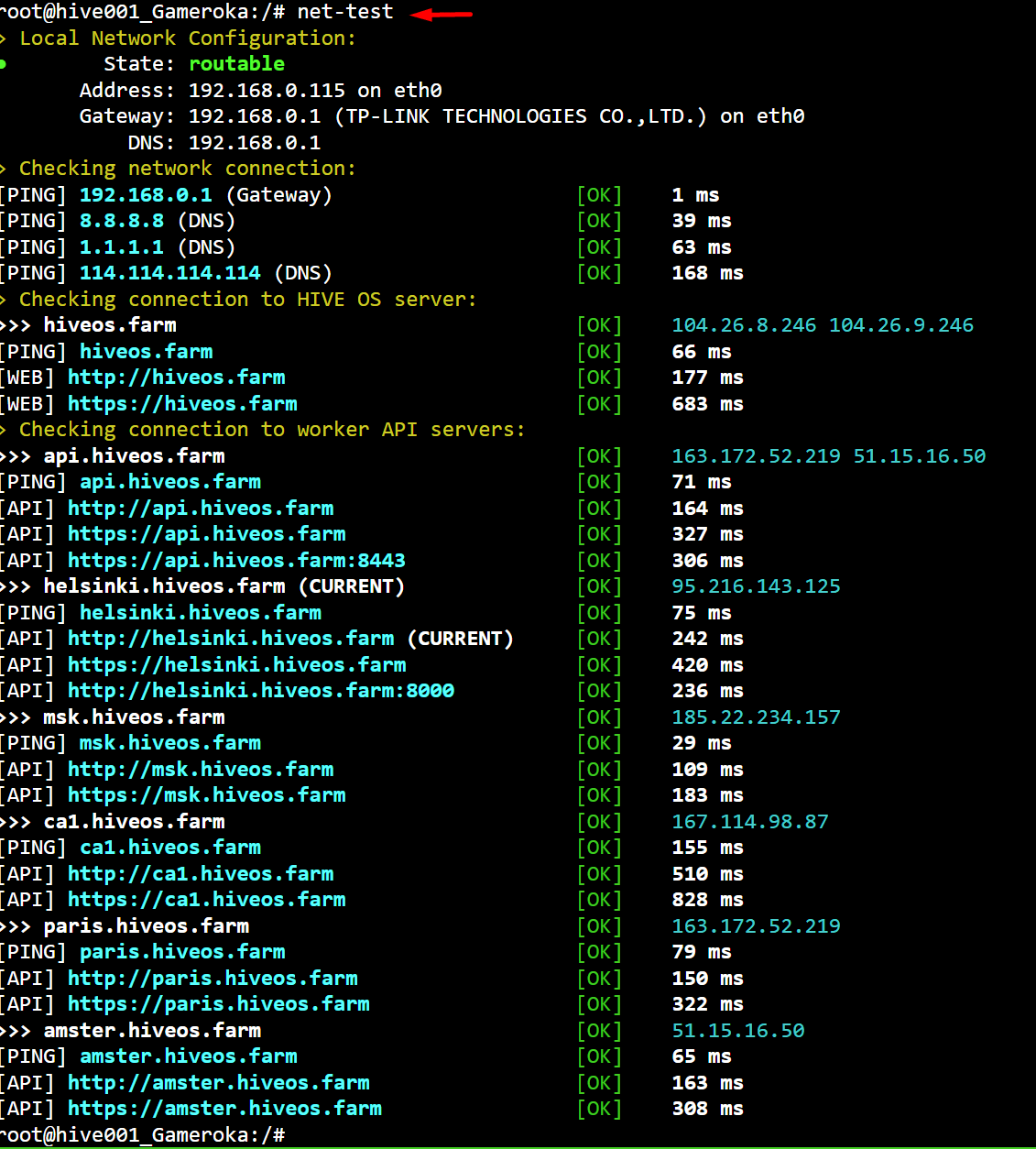
In order to check the availability of the Internet on your rig, you need a screen and a keyboard for a physical connection to the rig. After the Hiveon OS loading is complete, enter the command net-test . After you apply it, you will see the availability status of Hiveon OS servers.
What is error 511?
In most cases, this error occurs due to the malfunctioning of the video card’s riser. Please check the power connector on the riser for a burnt wire, and replace the riser.
What is DPM on AMD video cards?
DPM is a table of core frequencies and the corresponding voltages of these frequencies. This information can be checked with the amd-info command. The video card changes the core frequencies in steps according to this table.
The manufacturer with a large margin sets the voltages for each stage of the core frequency. Our task is to select the lowest voltage value for the selected core frequency specified in DPM, but at the same time to ensure that the card continues to mine steadily. In this way we get reduced consumption without losing performance. This is downvolt. Here are the examples:
- DPM 3 825
- DPM 4 875
- DPM 5 925
By default, Hiveon OS uses the value DPM 5. The factory value on Windows is DPM 7 Windows. Specifying core frequency works, but not on all the cards. But using the DPM value definitely works on all video cards.
How can rigs be merged /moved to another farm?
Go to the rig’s Settings:

Scroll down and click the Advanced settings button:

Select the desired farm from the drop-down list and click the Transfer button.:

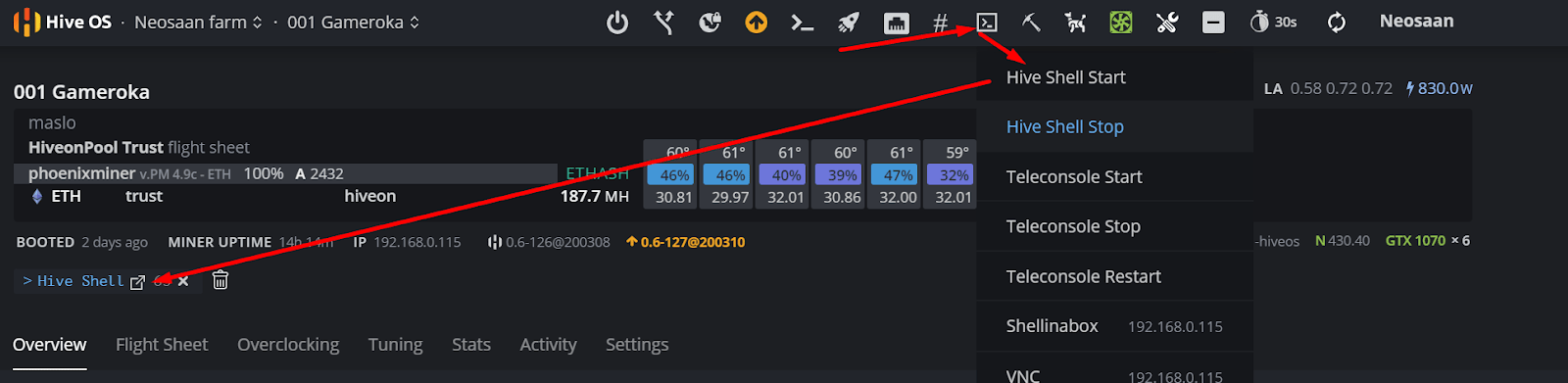
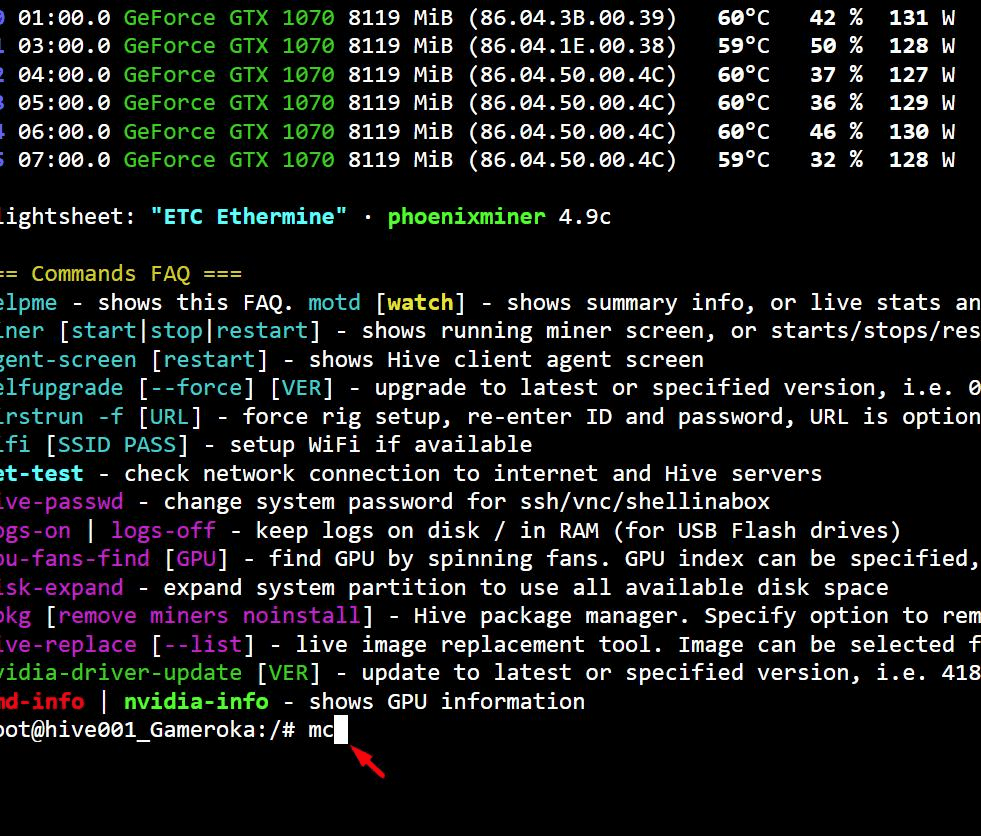
How to launch mc on the rig
To start the mc editor, launch Hive Shell on your worker. Then enter the mc command.
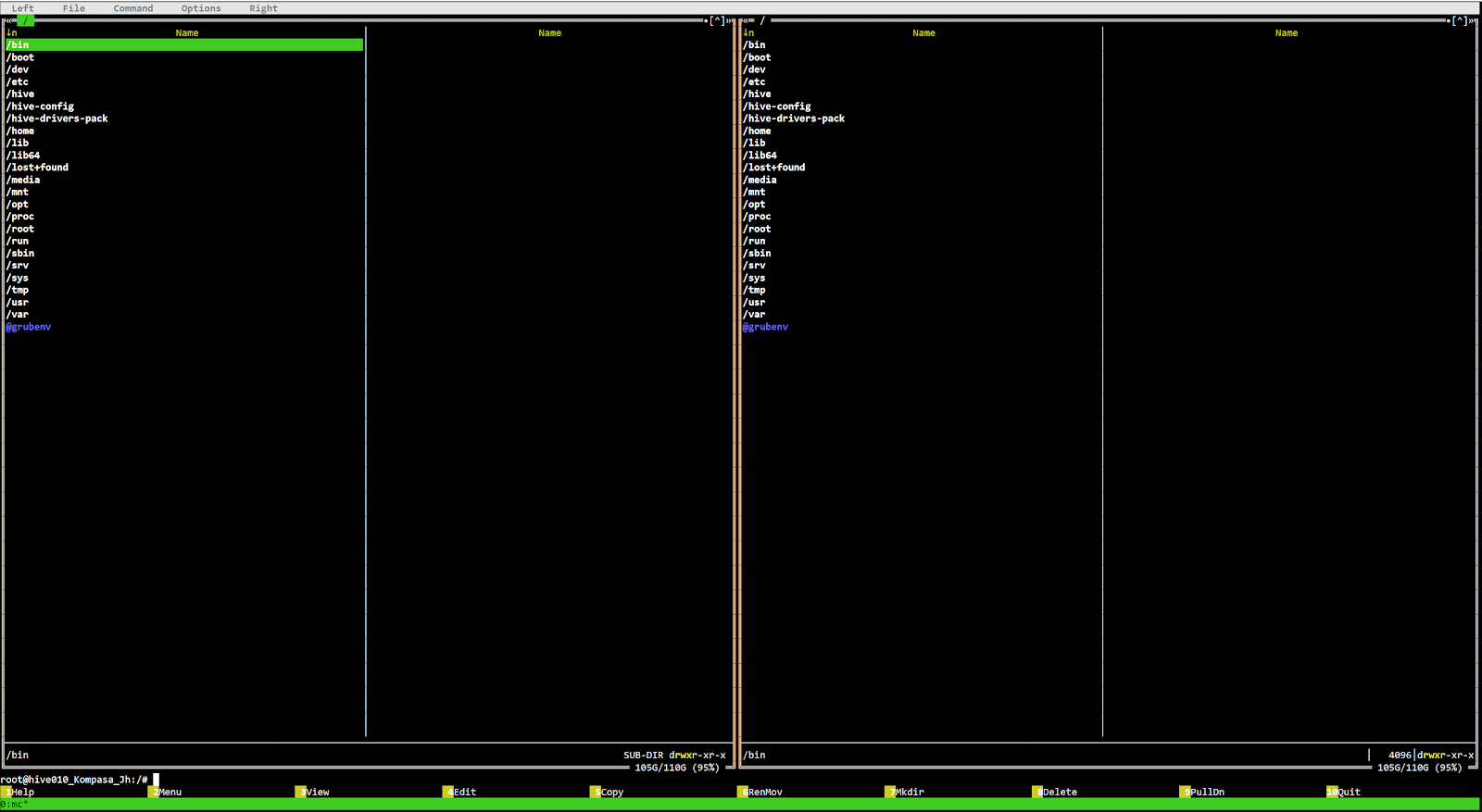
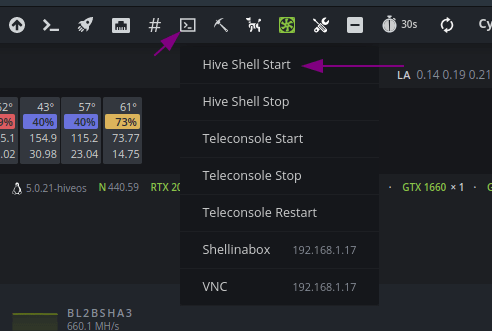
How can I check if the rig is really frozen using Hive-Shell?
Using Hive Shell, enter the working rig located in the same local network as the frozen one.
Enter this command: ssh user@”Ip_address_of_the_frozen_rig” :
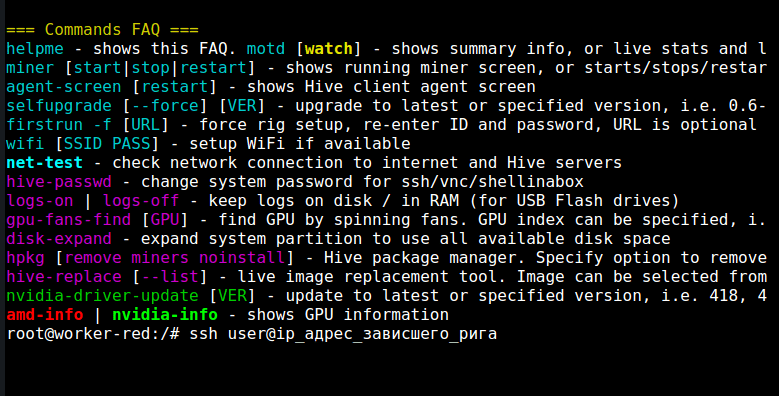
Then enter your password for this rig. The latest IP address of the rig can be checked in the Hiveon OS dashboard . Now you can check if the rig has really frozen or turned off, or if it is a glitch of the web-server.
The exit command will every time bring you back in the chain.
What is LA (Load Average)?
Load Average is the average number of executable processes over a given time. For example, if the hourly load average is 10, this means (for a uniprocessor system) that at any given time during that hour, 1 process is running, and 9 are ready to run (not blocked for input/output) and are waiting for the processor to become «free».
If you have Celeron G3930 with two cores, then LA 2 indicates 100% system load. For Ethash, this is very abnormal, but for modern algorithms — it is okay.
The maximum value of LA can be anything. This is the length of the queue to the processor, expressed in the number of cores of this processor. LA has always been counted as the number of computing devices required to complete the entire current task queue.
When mining Beam and Cuckoo on weak processors, LA can reach up to 3-4. If you don’t like the red color of the indicator, you can always set the threshold value here:
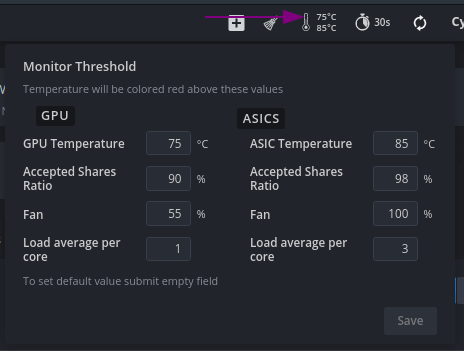
Three values: LA now / average LA per 5 minutes / average LA per 15 minutes .