Как работает хэширование

Если вы программист, то пользуетесь хэш-функциями каждый день. Они применяются в базах данных для оптимизации запросов, в структурах данных для ускорения работы, в безопасности для защиты данных. Почти каждое ваше взаимодействие с технологией тем или иным образом включает в себя хэш-функции.
Хэш-функции фундаментальны и используются повсюду .
Но что же такое хэш-функции и как они работают?
В этом посте я собираюсь развенчать мифы вокруг этих функций. Мы начнём с простой хэш-функции, узнаем, как проверить, хороша ли хэш-функция, а затем рассмотрим реальный пример применения хэш-функции: хэш-таблицу.
В оригинале статьи многие иллюстрации интерактивны
Что такое хэш-функция?
Хэш-функции — это функции, получающие на входе данные, обычно строку, и возвращающие число. При многократном вызове хэш-функции с одинаковыми входными данными она всегда будет возвращать одно и то же число, и возвращаемое число всегда будет находиться в гарантированном интервале. Этот интервал зависит от хэш-функции: в некоторых используются 32-битные целочисленные значения (то есть от 0 до 4 миллиардов), в других интервалы гораздо больше.
Если бы мы захотели написать на JavaScript имитацию хэш-функции, то она могла бы выглядеть так:
function hash(input)
Даже не зная, как используются хэш-функции, мы бы могли понять, что эта функция бесполезна. Давайте узнаем, как определить качественность хэш-функции, а чуть позже мы поговорим о том, как они используются в хэш-таблицах.
Какая хэш-функция может считаться хорошей?
Так как input может быть любой строкой, а возвращаемое число находится в каком-то гарантированном интервале, может случиться так, что при двух разных входных строках будет возвращено одно и то же число. Это называется «коллизией»; хорошие хэш-функции стремятся к минимизации создаваемых ими коллизий.
Однако полностью избавиться от коллизий невозможно. Если бы мы написали хэш-функцию, возвращающую число в интервале от 0 до 7, и передали бы ей 9 уникальных входных значений, то гарантированно получили бы как минимум 1 коллизию.

Выходные значения хорошо известной хэш-функции modulo 8 (деление на 8 с остатком). Какие бы 9 значений мы ни передали, есть всего 8 уникальных чисел, поэтому коллизии неизбежны. Цель заключается в том, чтобы их было как можно меньше.
Для визуализации коллизий я использую сетку. Каждый квадрат в сетке будет обозначать число, возвращаемое хэш-функцией. Вот пример сетки 8×2.
В дальнейшем при каждом хэшировании значения мы будем делать соответствующий ему квадрат в сетке чуть темнее. Смысл в том, чтобы наглядно показать, насколько хорошо хэш-функция избегает коллизий. Мы стремимся получить хорошее равномерное распределение. Будет понятно, что функция плоха, если у нас получатся скопления или паттерны из тёмных квадратов.

Вы сказали, что когда хэш-функция возвращает одинаковое значение для двух входных данных, это называется коллизией. Но если у нас будет хэш-функция, которая возвращает значения в большом интервале, а мы накладываем их на маленькую сетку, то не создадим ли мы множество коллизий, которые на самом деле не будут коллизиями? В нашей сетке 8×2 и 1, и 17 соответствуют второму квадрату.
Отличное замечание. Ты совершенно права, в нашей сетке будут возникать «псевдоколлизии». Но это приемлемо, потому что если хэш-функция хороша, то мы всё равно увидим равномерное распределение. Инкремент каждого квадрата на 100 — это столь же хорошее распределение, как и инкремент каждого квадрата на 1. Если мы получим хэш-функцию с большой степенью коллизий, то это всё равно будет бросаться в глаза. Вскоре мы сами в этом убедимся.
Давайте возьмём сетку побольше и хэшируем 1000 случайно сгенерированных строк. Анимация сетки показывает, как каждое входное значение хэшируется и помещается в сетку.
Значения распределяются равномерно, потому что мы используем хорошо изученную хэш-функцию под названием murmur3 . Эта функция широко используется в реальных приложениях благодаря своему отличному распределению, а также очень высокой скорости работы.
Как бы выглядела наша сетка, если бы мы использовали плохую хэш-функцию?
function hash(input) < let hash = 0; for (let c of input) < hash += c.charCodeAt(0); >return hash % 1000000; >Эта хэш-функция циклически обходит всю переданную ей строку и суммирует числовые значения каждого символа. Затем она делает так, чтобы значение находилось в интервале от 0 до 1000000 при помощи оператора деления с остатком ( % ). Назовём эту хэш-функцию stringSum .
Вот как она выглядит в сетке. Напомню, что это 1000 случайно сгенерированных строк, которые мы хэшируем.
Не сильно отличается от murmur3 . В чём же дело?
Проблема в том, что передаваемые на хэширование строки случайны. Давайте посмотрим, как ведёт себя каждая функция, когда входные данные не случайны: это будут числа от 1 до 1000, преобразованные в строки.

Теперь проблема стала очевиднее. Когда входные данные не случайны, выходные данные stringSum образуют паттерн. А сетка murmur3 выглядит так же, как и при случайных значениях.

Разница менее заметна, но мы всё равно видим паттерн в сетке stringSum . Функция murmur3 снова выглядит, как обычно.
В этом и состоит сила хорошей хэш-функции: какими бы ни были входные данные, выходные данные всегда распределены равномерно. Давайте поговорим о ещё одном способе визуализации этого, а затем расскажем, почему это важно.
▍ Лавинный эффект
Ещё один способ проверки хэш-функций — это так называемый «лавинный эффект». Это показатель того, какое количество битов меняется в выходном значении при изменении всего одного бита во входном значении. Чтобы можно было сказать, что хэш-функция имеет хороший лавинный эффект, смена одного бита во входном значении должна приводить в среднем к смене 50% битов в выходном значении.
Именно это свойство помогает хэш-функциям не создавать паттерны в сетке. Если небольшое изменение во входных данных приводит к небольшим изменениям в выходных, то возникнут паттерны. Паттерны — это показатели плохого распределения и повышенного уровня коллизий.
Ниже мы показали лавинный эффект на примере двух 8-битных двоичных чисел. Верхнее число — это входное значение, а нижнее — выходное значение murmur3 . Каждый раз во входном значении меняется один бит. Изменившиеся в выходном значении биты будут выделены зелёным , а неизменившиеся биты — оранжевым .
murmur3 проявляет себя хорошо, несмотря на то, что иногда меняется меньше 50% битов, а иногда больше. И это нормально, если в среднем получается 50%.
Давайте посмотрим, как ведёт себя stringSum .
А вот это уже отвратительно. Выходные данные равны входным, поэтому каждый раз меняется только один бит. И это логично, ведь stringSum просто суммирует числовое значение каждого символа в строке. Этот пример хэширует эквивалент одного символа, то есть выходное значение всегда будет таким же, как входное.
Почему всё это важно
Мы поговорили о нескольких способах определения качественности хэш-функций, но не обсудили, почему это важно. Давайте исправим это, рассмотрев хэш-таблицы (hash map).
Чтобы понять хэш-таблицы, нужно сначала понять, что такое map. Map — это структура данных, позволяющая хранить пары «ключ-значение». Вот пример на JavaScript:
let map = new Map(); map.set("hello", "world"); console.log(map.get("hello"));Здесь мы берём пару «ключ-значение» ( «hello» → «world» ) и сохраняем её в map. Затем мы выводим значение, связанное с ключом «hello» , то есть «world» .
Более интересным примером реального использования стал бы поиск анаграмм. Анаграмма — это когда два разных слова состоят из одинаковых букв, например, «апельсин» и «спаниель» или «кабан» и «банка». Если у вас есть список слов, и вы хотите найти все анаграммы, то можно отсортировать буквы в каждом слове по алфавиту и использовать эту строку как ключ структуры map.
let words = [ "antlers", "rentals", "sternal", "article", "recital", "flamboyant", ] let map = new Map(); for (let word of words) < let key = word .split('') .sort() .join(''); if (!map.has(key)) < map.set(key, []); >map.get(key).push(word); >В результате выполнения этого кода мы получаем map со следующей структурой:
▍ Реализация собственной простой хэш-таблицы
Хэш-таблицы — одна из множества реализаций map; также существует множество способов реализации хэш-таблиц. Простейший способ, который мы и покажем — это список списков. Внутренние списки в реальном мире часто называют «bucket», поэтому так мы их и будем называть. Хэш-функция применяется к ключу для определения того, в каком bucket должна храниться пара «ключ-значение», после чего эта пара «ключ-значение» добавляется в bucket.
Давайте рассмотрим простую реализацию хэш-таблицы на JavaScript. Мы изучим её снизу вверх, то есть сначала рассмотрим вспомогательные методы, а затем перейдём к реализациям set и get .
class HashMap < constructor() < this.bs = [[], [], []]; >>Мы начнём с создания класса HashMap с конструктором, настраивающим три bucket. Мы используем три bucket и короткое имя переменной bs , чтобы этот код удобно было просматривать на устройствах с маленькими экранами. В реальном коде можно создавать любое количество bucket (и придумать более осмысленные имена переменных).
class HashMap < // . bucket(key) < let h = murmur3(key); return this.bs[ h % this.bs.length ]; >>В методе bucket к переданному key применяется murmur3 , чтобы найти bucket, который нужно использовать. Это единственное место в нашем коде хэш-таблицы, где используется хэш-функция.
class HashMap < // . entry(bucket, key) < for (let e of bucket) < if (e.key === key) < return e; >> return null; > >Метод entry получает bucket и key и сканирует bucket, пока не найдёт элемент с указанным ключом. Если элемент не найден, возвращается null .
class HashMap < // . set(key, value) < let b = this.bucket(key); let e = this.entry(b, key); if (e) < e.value = value; return; >b.push(< key, value >); > >Метод set мы первым узнаём из предыдущих примеров Map на JavaScript. Он получает пару «ключ-значение» и сохраняет её в хэш-таблицу. Он делает это при помощи созданных ранее методов bucket и entry . Если элемент найден, то значение перезаписывается. Если элемент не найден, то пара «ключ-значение» добавляется в map. В JavaScript < key, value >— это более компактная запись < key: key, value: value >.
class HashMap < // . get(key) < let b = this.bucket(key); let e = this.entry(b, key); if (e) < return e.value; >return null; > >Метод get очень похож на set . Он использует bucket и entry для поиска элемента, связанного с переданным key , точно так же, как это делает set . Если элемент найден, возвращается его value . Если он не найден, то возвращается null .
Объём кода получился довольно большим. Главное, что нужно из него понять: наша хэш-таблица — это список списков, а хэш-функция используется для того, чтобы понять, в каком из списков хранить ключ и откуда его извлекать.
Вот визуальное представление этой хэш-таблицы. При помощи set добавляется новая пара «ключ-значение». Чтобы не усложнять визуализацию, если bucket должен «переполниться», то все bucket очищаются.
Так как мы используем в качестве хэш-функции murmur3 , то распределение между bucket оказывается хорошим. Можно ожидать частичный дисбаланс, но обычно распределение достаточно равномерное.
Чтобы получить значение из хэш-таблицы, мы сначала хэшируем ключ, чтобы понять, в каком из bucket будет находиться значение. Затем нам нужно сравнить ключ, который мы ищем, со всеми ключами в bucket.
Именно этот этап поиска мы минимизируем при помощи хэширования, и именно благодаря ему murmur3 оптимизирована по скорости. Чем быстрее хэш-функция, тем быстрее мы отыскиваем нужный bucket для поиска, и тем быстрее наша хэш-таблица в целом.
Кроме того, из-за этого так важно снижение количества коллизий. Если бы мы решили использовать имитацию хэш-функции из начала статьи, постоянно возвращающую 0, то поместили бы все пары «ключ-значение» в первый bucket. Для поиска любого элемента нам пришлось бы проверить все значения в хэш-таблице. При хорошей хэш-функции с хорошим распределением мы снижаем количество необходимых операций поиска до 1/N, где N — это количество bucket.
Давайте посмотрим, как проявляет себя здесь stringSum .
Любопытно: кажется, stringSum распределяет достаточно неплохо. Мы замечаем паттерн, но в целом распределение выглядит хорошим.

Наконец-то! Победа stringSum ! Я знала, что она когда-нибудь пригодится.
Не торопись, Хаски. Нам нужно обсудить серьёзную проблему. Распределение выглядит приемлемым при этих последовательных числах, однако мы видели, что у stringSum плохой лавинный эффект. Всё это не кончится ничем хорошим.
Коллизии в реальном мире
Давайте рассмотрим два массива данных из реального мира: IP-адреса и английские слова. Я возьму 100 000 000 случайных IP-адресов и 466 550 английских слов, хэширую их murmur3 и stringSum , а потом посмотрю, сколько коллизий мы получим.
| murmur3 | stringSum | |
| Коллизии | 1 156 959 | 99 999 566 |
| 1,157% | 99,999% |
Английские слова
| murmur3 | stringSum | |
| Коллизии | 25 | 464 220 |
| 0,005% | 99,5% |
Когда мы используем хэш-таблицы в реальности, то обычно не храним в них случайные значения. В качестве примера можно представить подсчёт количества запросов, в которых встречался IP-адрес, в коде вычисления ограничения частоты доступа к серверу. Или код, подсчитывающий количество вхождений слов в книгах на протяжении веков для отслеживания их происхождения и популярности. В этих областях применения stringSum ужасна из-за своей чрезвычайно высокой частоты коллизий.
Синтетические коллизии
А теперь настало время плохих новостей для murmur3 . Нам стоит учитывать не только коллизии, вызванные схожестью входных данных. Взгляните:
Что здесь происходит? Почему все эти бессмысленные строки хэшируются в одинаковое число?
Я хэшировал 141 триллион случайных строк, чтобы найти значения, при использовании murmur3 хэшируемые в число 1228476406 . Хэш-функции всегда должны возвращать одинаковый результат для конкретного входного значения, поэтому можно найти коллизии простым перебором.

Простите, 141 триллион ? Это… 141 и 12 нулей?
Да, и это заняло у меня всего 25 минут. Компьютеры очень быстры.
Наличие у злоумышленников лёгкого доступа к коллизиям может иметь катастрофические последствия, если ваше ПО создаёт хэш-таблицы из пользовательского ввода. Возьмём для примера HTTP-заголовки. HTTP-запрос выглядит так:
GET / HTTP/1.1 Accept: */* Accept-Encoding: gzip, deflate Connection: keep-alive Host: google.comВам необязательно понимать все слова, достаточно знать, что первая строка — это запрашиваемый путь, а все остальные строки — это заголовки. Заголовки — это пары Key: Value , поэтому HTTP-серверы обычно хранят их в таблицах. Ничто не мешает нам отправить любые нужные заголовки, поэтому мы можем быть очень жестокими и передать заголовки, которые, как нам известно, вызовут коллизии. Это может существенно замедлить сервер.
И это не теоретические рассуждения. Если вы поищите «HashDoS», то сможете найти ещё множество примеров этого. В середине 2000-х это была очень серьёзная проблема.
Есть несколько способов решения этой проблемы конкретно для HTTP-серверов: например, игнорирование бессмысленных ключей заголовков и ограничение количества хранимых заголовков. Однако современные хэш-функции наподобие murmur3 предоставляют более общее решение: рандомизацию.
Выше в этом посте мы показали несколько примеров реализаций хэш-функций. Эти реализации получают единственный аргумент: input . Многие из современных хэш-функций получают второй параметр: порождающее значение ( seed ) (иногда называемое «солью» ( salt )). В случае murmur3 этим seed является число.
Пока мы использовали в качестве seed значение 0. Давайте посмотрим, что произойдёт с собранными мной коллизиями при использовании seed, равного 1.
Именно так: простой заменой 0 на 1 мы избавились от всех коллизий. В этом и заключается предназначение seed: он непредсказуемым образом рандомизирует выходные данные хэш-функции. То, как он этого достигает, не относится к теме нашей статьи, каждая хэш-функция делает это по-своему.
Хэш-функция по-прежнему возвращает одинаковые выходные данные для одинаковых входных данных, только теперь входные данные — это сочетание input и seed . Те значения, у которых возникают коллизии при одном seed, не приводят к коллизиям при использовании другого. Языки программирования в начале процесса часто генерируют случайное число для использования в качестве seed, чтобы каждый раз при запуске программы seed различался. Если я злоумышленник, не знающий seed, то больше не могу стабильно наносить ущерб.
Если внимательно присмотреться к двум предыдущим визуализациям, то можно заметить, что в них хэшируются одинаковые значения, но они создают разные значения хэша. Из этого следует, что если вы хэшируете значение с одним seed, и хотите в будущем выполнять сравнения с ним, то необходимо использовать одинаковый seed.
Использование разных значений для разных seed не влияет на применение хэш-таблиц, потому что хэш-таблицы существуют только во время выполнения программы. При условии, что на протяжении всего срока работы программы вы используете один seed, ваши хэш-таблицы будут без проблем работать. Если вам нужно сохранить значения хэша вне своей программы, например, в файл, то обязательно знать, какой seed использовался.
Песочница
По традиции я создал песочницу, в которой вы можете писать собственные хэш-функции и визуализировать их в сетках, как в этой статье. Поэкспериментировать с песочницей можно здесь.
Заключение
Мы поговорили о том, что такое хэш-функции, рассказали о некоторых способах оценки их качества, объяснили, что происходит, когда они плохие; также мы узнали о нескольких способах, которыми их могут взломать злоумышленники.
Вселенная хэш-функций велика, и в этом посте мы рассказали о ней лишь поверхностно. Мы не говорили о криптографическом и некриптографическом хэшировании, коснулись лишь одного из тысяч способов применения хэш-функций и вообще не обсудили способ работы современных хэш-функций.
Если вам интересна эта тема, то рекомендую изучить следующие материалы:
- https://github.com/rurban/smhasher: этот репозиторий — золотой стандарт тестирования качества хэш-функций. Он проводит кучу тестов, выполняя сравнение с большим количеством хэш-функций, и представляет результаты в виде большой таблицы. Может быть сложно понять, для чего нужны все эти тесты, но это самая современная система для тестирования хэш-функций.
- https://djhworld.github.io/hyperloglog/ — это интерактивная статья о структуре данных под названием HyperLogLog. Она используется для эффективного подсчёта уникальных элементов в огромных массивах данных. Для этого она очень хитро применяет хэширование.
- https://www.gnu.org/software/gperf/ — это ПО, которому можно передать ожидаемое множество элементов, которые нужно хэшировать, и оно автоматически сгенерирует «идеальную» хэш-функцию.
Благодарности
Благодарю всех, кто читал ранние черновики статьи и давал бесценные отзывы.
Подскажите пожалуйста, что такое «хеширование» ?
хеширование-это что то вроде чтения и проверки файлов для последующей выкладки в интернет или на сайты!вот.
Тимофей МешковУченик (217) 6 лет назад
это Кеширование!
Остальные ответы
Офигет, знаток, блин. Хеширование, это система шифрования паролей с получением контрольной суммы (хеша). В дальнейшем при проверке пароля, идет сверка не с самим паролем а хеш-суммы введенного пароля и хеш-суммы заданного.
Хеширование (англ. Collision-Resistant Hash Functions) — преобразование входного массива данных произвольной длины в выходную битовую строку фиксированной длины таким образом, чтобы изменение входных данных приводило к непредсказуемому изменению выходных данных. Такие преобразования также называются хеш-функциями или функциями свёртки, а их результаты называют хешем, хеш-кодом или дайджестом сообщения (англ. message digest).
В общем случае это применение можно описать, как проверка некоторой информации на идентичность оригиналу, без использования оригинала. Для сверки используется хеш-значение проверяемой информации. Различают два основных направления этого применения:
Проверка на наличие ошибок
Например, контрольная сумма может быть передана по каналу связи вместе с основным текстом. На приёмном конце, контрольная сумма может быть рассчитана заново и её можно сравнить с переданным значением. Если будет обнаружено расхождение, то это значит, что при передаче возникли искажения и можно запросить повтор.
Бытовым аналогом хеширования в данном случае может служить приём, когда при переездах в памяти держат количество мест багажа. Тогда для проверки не нужно вспоминать про каждый чемодан, а достаточно их посчитать. Совпадение будет означать, что ни один чемодан не потерян. То есть, количество мест багажа является его хеш-кодом.
Проверка парольной фразы
В большинстве случаев парольные фразы не хранятся на целевых объектах, хранятся лишь их хеш-значения. Хранить парольные фразы нецелесообразно, т.к. в случае несанкционированного доступа к файлу с фразами злоумышленник узнает все парольные фразы и сразу сможет ими воспользоваться, а при хранении хеш-значений он узнает лишь хеш-значения, которые не обратимы в исходные данные, в данном случае в парольную фразу. В ходе процедуры аутентификации вычисляется хеш-значение введённой парольной фразы, и сравнивается с сохранённым.
Бытовым примером в данном случае может служить ОС Windows XP. В ней хранятся лишь хеш-значения парольных фраз из учётных записей пользователей.
Сергей СергеевМастер (2190) 10 лет назад
Есть же умные люди!
AlexKudeМыслитель (6040) 7 лет назад
Очень понравились бытовые примеры. Я ужасно долго не мог понять, что это такое и вот наконец понял:)
Хеширование — преобразование входного массива данных в короткое число фиксированной длины (которое называется хешем или хеш-кодом) таким образом, чтобы с одной стороны, это число было значительно короче исходных данных, а с другой стороны, с большой вероятностью однозначно им соответствовало. Преобразование выполняется при помощи хеш-функции. Ясно, что в общем случае однозначного соответствия между исходными данными и хеш-кодом быть не может. Обязательно будут возможны массивы данных, дающих одинаковые хеш-коды, но вероятность таких совпадений в каждой конкретной задаче должна быть сведена к минимуму выбором хеш-функции.
Простым примером хеширования может служить нахождение циклической контрольной суммы, когда берётся текст (или другие данные) и суммируются коды входящих в него символов, а затем отбрасываются все цифры, за исключением нескольких последних. Полученное число может являться примером хеш-кода исходного текста.
Кроме этого, существует много других способов хеширования, подходящих к различным задачам.
Среди множества существующих хеш-функций принято выделять криптографически стойкие, применяемые в криптографии.
В современной жизни часто применяется MD5-хэш. Его используют для шифрования паролей и дальнейшей проверки.
Например в ICQ, когда Вы вводите пароль, то программа обрабатывает его хэш-функцией, и передает на сервер авторизации, а сервер уже сравнивает полученный хэш с имеющимся в его базе. Так как многие хэш-функции являются необратимыми, т.е. на основании хэша получить данные нельзя, то такая авторизация считается достаточно безопасной.
Эта же функция применяется в сети EDonkey для проверки контрольных сумм файлов и отслеживания одинаковых файлов у разных пользователей. (В этом случае обрабатывается весь файл по-байтово, и строка с хэшем получается длинной, но много раз меньшей, чем сам файл).
Самой простой хэш функцией считается функция проверки четности (CRC), которая повсеместно используется при копировании файлов, а точнее при проверке идентичности исходного файла и его копии.
Хеширование (англ. Collision-Resistant Hash Functions) — преобразование входного массива данных произвольной длины в выходную битовую строку фиксированной длины таким образом, чтобы изменение входных данных приводило к непредсказуемому изменению выходных данных. Такие преобразования также называются хеш-функциями или функциями свёртки, а их результаты называют хешем, хеш-кодом или дайджестом сообщения (англ. message digest).
В общем случае однозначного соответствия между исходными данными и хеш-кодом быть не может. Существует множество массивов данных, дающих одинаковые хеш-коды (так называемые коллизии), и каждая хэш-функция должна оцениваться по стойкости к возникновению коллизий. В разных задачах выдвигаются различные требования с стойкости хэш-функций.
Простым примером хеширования может служить нахождение контрольной суммы сообщения: сумма кодов всех входящих в него символов, от которой берётся несколько последних цифр. Полученное число является примером хеш-кода исходного сообщения. Существует множество способов хеширования, подходящих к различным задачам.
Среди множества существующих хеш-функций принято выделять криптографически стойкие, применяемые в криптографии.
Криптографическая хеш-функция должна обеспечивать:
стойкость к коллизиям (два различных набора данных должны иметь различные результаты преобразования)
необратимость (невозможность вычислить исходные данные по результату преобразования)
Хеш-функции также используются в некоторых структурах данных — хеш-таблицаx и декартовых деревьях. Требования к хеш-функции в этом случае другие:
хорошая перемешиваемость данных
быстрый алгоритм вычисления
Источник: Википедия : http://ru.wikipedia.org
Валерий ЧистяковМастер (1181) 16 лет назад
Может Кэширование?))
Этот термин к разному относиться.Например Инет-кэширование:
Когда Вы просматриваете различные ресурсы, они могут быть сохранены (прокэшированы) на жестком диске (или proxy-сервере). В следующий раз, при обращении к тому же ресурсу для увеличения скорости загрузки странички, файлы, картинки и прочие прокэшированные ресурсы, будут загружаться с жесткого диска, а не с удаленного сервера. Это позволяет уменьшить время загрузки страниц и объем входящего трафика.
хэширование — это процесс получения уникального (чаще цифрового) идентификатора для объекта.
Например, в вашем нике Alex можно каждую букву заменить на какую-то цифру, а можно сказать, что Alex = 1. Причем алгоритм, который говорит, что Alex = 1 и 1 = Alex должен быть уникален. То есть если видим «1» на «ответах», значит Alex и никто больше.
делается такое присвоение идентификатора автоматически. это делается с помощью хэш-функции. то есть f(«Alex») -> «1» и есть хэш-функция (кодирование) . обратное хэширование — восстановление исходного значения f2(«1») -> «Alex».
применение хэширования как раз идет от уникальности полученного хэш-кода. Хотя бы потому, что он очень короткий
Что такое хэш-сумма?
Пожалуйста, не нужно говорить, что это результат алгоритма шифрования MD5, мне википедия этим все уши прожужжала. Мне нужно объяснить, что делает этот алгоритм, чтобы понять, что является его результатом. По слову «сумма» мне почему-то кажется, что это сумма всех битов или байтов. Объясните, если я не прав. Заранее, спасибо.
Лучший ответ
Обычно говорят хэш-функция. Функция, принимающая строку неопределенной длины и возвращающая число огранниченного диапазона (его часто записывают в 16-ричной форме), причем незначительное изменение исходной строки (например, замена одного бита) приводит к значительному изменению результата.
MD5 — классический пример, хотя уже устаревший, сейчас рекомендуют MD6, SHA-2, SHA-3. Базовое применение — хэш-таблицы (отсюда и название) и контрольные суммы (видимо, отсюда перекочевало слово «сумма»).
Остальные ответы
Контрольная сумма для сверки файлов с источника.
CenturionЗнаток (256) 7 лет назад
А можно не на уровне ламера? Поподробнее, пожалуйста.
Алехандро Искусственный Интеллект (349865) Что тебе конкретно. Файл у тебя на ПК сравнивается с файлом на Сервере или еще где-то Хеш суммой
Посмотри что такое хеширование, потом поймешь.
Считай это ключ достоверности
сумма всех битов или байтов защитит от случайного сбоя, но не от предумышленного.
MD5 — сложный алгоритм, подобрать его очень большие вычислительные затраты. Сейчас устарел.
В общем не расшифруемая шифровка, для скрытия паролей от расшифрования но можно сравнивать хэш суммы
Вот к примеру слово — ТЕКСТ — e5ef89d19ab8b41051c33f876e9d0854
А вот текст=asiuhuhfweuiwehwuufsnufsnnfuufuffnufsnufsnufdsnufdsnndfsusdfunsdfnufnusdnudfsnudfsnsdf
Его хэш сумма составляет: 885fd43345e6cd41de4a90e7a21cb9d2
Хэш не расшифровывается никогда, но можно расшифровать подбором
Что такое Хэширование? Под капотом блокчейна
Очень многие из вас, наверное, уже слышали о технологии блокчейн, однако важно знать о принципе работы хэширования в этой системе. Технология Блокчейн является одним из самых инновационных открытий прошлого века. Мы можем так заявить без преувеличения, так как наблюдаем за влиянием, которое оно оказало на протяжении последних нескольких лет, и влиянием, которое оно будет иметь в будущем. Для того чтобы понять устройство и предназначение самой технологии блокчейн, сначала мы должны понять один из основных принципов создания блокчейна.
Так что же такое хэширование?
Простыми словами, хэширование означает ввод информации любой длины и размера в исходной строке и выдачу результата фиксированной длины заданной алгоритмом функции хэширования. В контексте криптовалют, таких как Биткоин, транзакции после хэширования на выходе выглядят как набор символов определённой алгоритмом длины (Биткоин использует SHA-256).

Input- вводимые данные, hash- хэш
Посмотрим, как работает процесс хэширования. Мы собираемся внести определенные данные. Для этого, мы будем использовать SHA-256 (безопасный алгоритм хэширования из семейства SHA-2, размером 256 бит).
Как видите, в случае SHA-256, независимо от того, насколько объёмные ваши вводимые данные (input), вывод всегда будет иметь фиксированную 256-битную длину. Это крайне необходимо, когда вы имеете дело с огромным количеством данных и транзакций. Таким образом, вместо того, чтобы помнить вводимые данные, которые могут быть огромными, вы можете просто запомнить хэш и отслеживать его. Прежде чем продолжать, необходимо познакомиться с различными свойствами функций хэширования и тем, как они реализуются в блокчейн.
Криптографические хэш-функции
Криптографическая хэш-функция — это специальный класс хэш-функций, который имеет различные свойства, необходимые для криптографии. Существуют определенные свойства, которые должна иметь криптографическая хэш-функция, чтобы считаться безопасной. Давайте разберемся с ними по очереди.
Свойство 1: Детерминированние
Это означает, что независимо от того, сколько раз вы анализируете определенный вход через хэш-функцию, вы всегда получите тот же результат. Это важно, потому что если вы будете получать разные хэши каждый раз, будет невозможно отслеживать ввод.
Свойство 2: Быстрое вычисление
Хэш-функция должна быть способна быстро возвращать хэш-вход. Если процесс не достаточно быстрый, система просто не будет эффективна.
Свойство 3: Сложность обратного вычисления
Сложность обратного вычисления означает, что с учетом H (A) невозможно определить A, где A – вводимые данные и H(А) – хэш. Обратите внимание на использование слова “невозможно” вместо слова “неосуществимо”. Мы уже знаем, что определить исходные данные по их хэш-значению можно. Возьмем пример.
Предположим, вы играете в кости, а итоговое число — это хэш числа, которое появляется из кости. Как вы сможете определить, что такое исходный номер? Просто все, что вам нужно сделать, — это найти хэши всех чисел от 1 до 6 и сравнить. Поскольку хэш-функции детерминированы, хэш конкретного номера всегда будет одним и тем же, поэтому вы можете просто сравнить хэши и узнать исходный номер.
Но это работает только тогда, когда данный объем данных очень мал. Что происходит, когда у вас есть огромный объем данных? Предположим, вы имеете дело с 128-битным хэшем. Единственный метод, с помощью которого вы должны найти исходные данные, — это метод «грубой силы». Метод «грубой силы» означает, что вам нужно выбрать случайный ввод, хэшировать его, а затем сравнить результат с исследуемым хэшем и повторить, пока не найдете совпадение.
Итак, что произойдет, если вы используете этот метод?
- Лучший сценарий: вы получаете свой ответ при первой же попытке. Вы действительно должны быть самым счастливым человеком в мире, чтобы это произошло. Вероятность такого события ничтожна.
- Худший сценарий: вы получаете ответ после 2 ^ 128 — 1 раз. Это означает, что вы найдете свой ответ в конце всех вычислений данных (один шанс из 340282366920938463463374607431768211456)
- Средний сценарий: вы найдете его где-то посередине, поэтому в основном после 2 ^ 128/2 = 2 ^ 127 попыток. Иными словами, это огромное количество.
Свойство 4: Небольшие изменения в вводимых данных изменяют хэш
Даже если вы внесете небольшие изменения в исходные данные, изменения, которые будут отражены в хэше, будут огромными. Давайте проверим с помощью SHA-256:

Видите? Даже если вы только что изменили регистр первой буквы, обратите внимание, насколько это повлияло на выходной хэш. Это необходимая функция, так как свойство хэширования приводит к одному из основных качеств блокчейна – его неизменности (подробнее об этом позже).
Свойство 5: Коллизионная устойчивость
Учитывая два разных типа исходных данных A и B, где H (A) и H (B) являются их соответствующими хэшами, для H (A) не может быть равен H (B). Это означает, что, по большей части, каждый вход будет иметь свой собственный уникальный хэш. Почему мы сказали «по большей части»? Давайте поговорим об интересной концепции под названием «Парадокс дня рождения».
Что такое парадокс дня рождения?
Если вы случайно встречаете незнакомца на улице, шанс, что у вас совпадут даты дней рождений, очень мал. Фактически, если предположить, что все дни года имеют такую же вероятность дня рождения, шансы другого человека, разделяющего ваш день рождения, составляют 1/365 или 0,27%. Другими словами, он действительно низкий.
Однако, к примеру, если собрать 20-30 человек в одной комнате, шансы двух людей, разделяющих тот же день, резко вырастает. На самом деле, шанс для 2 человек 50-50, разделяющих тот же день рождения при таком раскладе.
Как это применяется в хэшировании?
Предположим, у вас есть 128-битный хэш, который имеет 2 ^ 128 различных вероятностей. Используя парадокс дня рождения, у вас есть 50% шанс разбить коллизионную устойчивость sqrt (2 ^ 128) = 2 ^ 64.
Как вы заметили, намного легче разрушить коллизионную устойчивость, нежели найти обратное вычисление хэша. Для этого обычно требуется много времени. Итак, если вы используете такую функцию, как SHA-256, можно с уверенностью предположить, что если H (A) = H (B), то A = B.
Свойство 6: Головоломка
Свойства Головоломки имеет сильнейшее воздействие на темы касающиеся криптовалют (об этом позже, когда мы углубимся в крипто схемы). Сначала давайте определим свойство, после чего мы подробно рассмотрим каждый термин.
Для каждого выхода «Y», если k выбран из распределения с высокой мин-энтропией, невозможно найти вводные данные x такие, что H (k | x) = Y.
Вероятно, это, выше вашего понимания! Но все в порядке, давайте теперь разберемся с этим определением.
В чем смысл «высокой мин-энтропии»?
Это означает, что распределение, из которого выбрано значение, рассредоточено так, что мы выбираем случайное значение, имеющее незначительную вероятность. В принципе, если вам сказали выбрать число от 1 до 5, это низкое распределение мин-энтропии. Однако, если бы вы выбрали число от 1 до бесконечности, это — высокое распределение мин-энтропии.
Что значит «к|х»?
«|» обозначает конкатенацию. Конкатенация означает объединение двух строк. Например. Если бы я объединила «голубое» и «небо», то результатом было бы «голубоенебо».
Итак, давайте вернемся к определению.
Предположим, у вас есть выходное значение «Y». Если вы выбираете случайное значение «К», невозможно найти значение X, такое, что хэш конкатенации из K и X, выдаст в результате Y.
Еще раз обратите внимание на слово «невозможно», но не исключено, потому что люди занимаются этим постоянно. На самом деле весь процесс майнинга работает на этом (подробнее позже).
Примеры криптографических хэш-функций:
- MD 5: Он производит 128-битный хэш. Коллизионная устойчивость была взломана после ~2^21 хэша.
- SHA 1: создает 160-битный хэш. Коллизионная устойчивость была взломана после ~2^61 хэша.
- SHA 256: создает 256-битный хэш. В настоящее время используется в Биткоине.
- Keccak-256: Создает 256-битный хэш и в настоящее время используется Эфириуме.
1. Указатели
2. Связанные списки
Указатели
В программировании указатели — это переменные, в которых хранится адрес другой переменной, независимо от используемого языка программирования.
Например, запись int a = 10 означает, что существует некая переменная «a», хранящая в себе целочисленное значение равное 10. Так выглядит стандартная переменная.
Однако, вместо сохранения значений, указатели хранят в себе адреса других переменных. Именно поэтому они и получили свое название, потому как буквально указывают на расположение других переменных.
Связанные списки
Связанный список является одним из наиболее важных элементов в структурах данных. Структура связанного списка выглядит следующим образом:

*Head – заголовок; Data – данные; Pointer – указатель; Record – запись; Null – ноль
Это последовательность блоков, каждый из которых содержит данные, связанные со следующим с помощью указателя. Переменная указателя в данном случае содержит адрес следующего узла, благодаря чему выполняется соединение. Как показано на схеме, последний узел отмечен нулевым указателем, что означает, что он не имеет значения.
Важно отметить, что указатель внутри каждого блока содержит адрес предыдущего. Так формируется цепочка. Возникает вопрос, что это значит для первого блока в списке и где находится его указатель?
Первый блок называется «блоком генезиса», а его указатель находится в самой системе. Выглядит это следующим образом:

*H ( ) – Хэшированные указатели изображаются таким образом
Если вам интересно, что означает «хэш-указатель», то мы с радостью поясним.
Как вы уже поняли, именно на этом основана структура блокчейна. Цепочка блоков представляет собой связанный список. Рассмотрим, как устроена структура блокчейна:
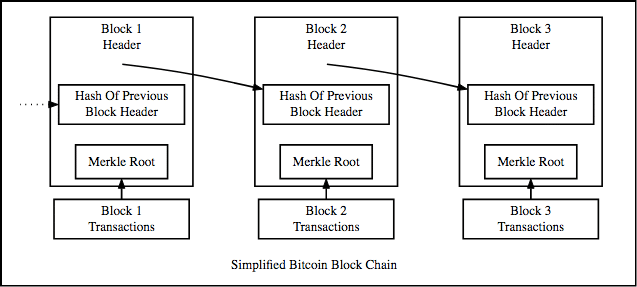
* Hash of previous block header – хэш предыдущего заголовка блока; Merkle Root – Корень Меркла; Transactions – транзакции; Simplified Bitcoin Blockchain – Упрощенный блокчейн Биткоина.
Блокчейн представляет собой связанный список, содержащий данные, а так же указатель хэширования, указывающий на предыдущий блок, создавая таким образов связную цепочку. Что такое хэш-указатель? Он похож на обычный указатель, но вместо того, чтобы просто содержать адрес предыдущего блока, он также содержит хэш данных, находящихся внутри предыдущего блока. Именно эта небольшая настройка делает блокчейн настолько надежным. Представим на секунду, что хакер атакует блок 3 и пытается изменить данные. Из-за свойств хэш-функций даже небольшое изменение в данных сильно изменит хэш. Это означает, что любые незначительные изменения, произведенные в блоке 3, изменят хэш, хранящийся в блоке 2, что, в свою очередь, изменит данные и хэш блока 2, а это приведет к изменениям в блоке 1 и так далее. Цепочка будет полностью изменена, а это невозможно. Но как же выглядит заголовок блока?

* Prev_Hash – предыдущий хэш; Tx – транзакция; Tx_Root – корень транзакции; Timestamp – временная отметка; Nonce – уникальный символ.
Заголовок блока состоит из следующих компонентов:
· Версия: номер версии блока
· Время: текущая временная метка
· Текущая сложная цель (См. ниже)
· Хэш предыдущего блока
· Уникальный символ (См. ниже)
· Хэш корня Меркла
Прямо сейчас, давайте сосредоточимся на том, что из себя представляет хэш корня Меркла. Но до этого нам необходимо разобраться с понятием Дерева Меркла.
Что такое Дерево Меркла?

Источник: Wikipedia
На приведенной выше диаграмме показано, как выглядит дерево Меркла. В дереве Меркла каждый нелистовой узел является хэшем значений их дочерних узлов.
Листовой узел: Листовые узлы являются узлами в самом нижнем ярусе дерева. Поэтому, следуя приведенной выше схеме, листовыми будут считаться узлы L1, L2, L3 и L4.
Дочерние узлы: Для узла все узлы, находящиеся ниже его уровня и которые входят в него, являются его дочерними узлами. На диаграмме узлы с надписью «Hash 0-0» и «Hash 0-1» являются дочерними узлами узла с надписью «Hash 0».
Корневой узел: единственный узел, находящийся на самом высоком уровне, с надписью «Top Hash» является корневым.
Так какое же отношение Дерево Меркла имеет к блокчейну?
Каждый блок содержит большое количество транзакций. Будет очень неэффективно хранить все данные внутри каждого блока в виде серии. Это сделает поиск какой-либо конкретной операции крайне громоздким и займет много времени. Но время, необходимое для выяснения, на принадлежность конкретной транзакции к этому блоку или нет, значительно сокращается, если Вы используете дерево Меркла.
Давайте посмотрим на пример на следующем Хэш-дереве:

Изображение предоставлено проектом: Coursera
Теперь предположим, я хочу узнать, принадлежат ли эти данные блоку или нет:

Вместо того, чтобы проходить через сложный процесс просматривания каждого отдельного процесса хэша, а также видеть принадлежит ли он данным или нет, я просто могу отследить след хэша, ведущий к данным:
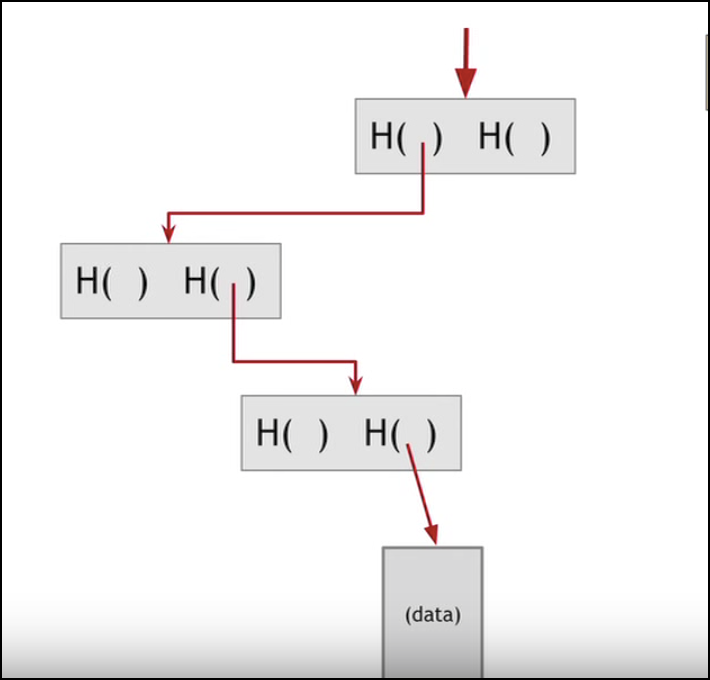
Это значительно сокращает время.
Хэширование в майнинге: крипто-головоломки.
Когда мы говорим «майнинг», в основном, это означает поиск нового блока, который будет добавлен в блокчейн. Майнеры всего мира постоянно работают над тем, чтобы убедиться, что цепочка продолжает расти. Раньше людям было проще работать, используя для майнинга лишь свои ноутбуки, но со временем они начали формировать «пулы», объединяя при этом мощность компьютеров и майнеров, что может стать проблемой. Существуют ограничения для каждой криптовалюты, например, для биткоина они составляют 21 миллион. Между созданием каждого блока должен быть определенный временной интервал заданный протоколом. Для биткоина время между созданием блока занимает всего 10 минут. Если бы блокам было разрешено создаваться быстрее, это привело бы к:
- Большому количеству коллизий: будет создано больше хэш-функций, которые неизбежно вызовут больше коллизий.
- Большому количеству брошенных блоков: Если много майнеров пойдут впереди протокола, они будут одновременно хаотично создавать новые блоки без сохранения целостности основной цепочки, что приведет к «осиротевшим» блокам.
Процесс Майнинга
Примечание: в этом разделе мы будем говорить о выработке биткоинов.
Когда протокол Биткоина хочет добавить новый блок в цепочку, майнинг – это процедура, которой он следует. Всякий раз, когда появляется новый блок, все их содержимое сначала хэшируется. Если подобранный хэш больше или равен, установленному протоколом уровню сложности, он добавляется в блокчейн, а все в сообществе признают новый блок.
Однако, это не так просто. Вам должно очень повезти, чтобы получить новый блок таким образом. Так как, именно здесь присваивается уникальный символ. Уникальный символ (nonce) — это одноразовый код, который объединен с хэшем блока. Затем эта строка вновь меняется и сравнивается с уровнем сложности. Если она соответствует уровню сложности, то случайный код изменяется. Это повторяется миллион раз до тех пор, пока требования не будут наконец выполнены. Когда же это происходит, то блок добавляется в цепочку блоков.
Подводя итоги:
• Выполняется хэш содержимого нового блока.
• К хэшу добавляется nonce (специальный символ).
• Новая строка снова хэшируется.
• Конечный хэш сравнивается с уровнем сложности, чтобы проверить меньше он его или нет
• Если нет, то nonce изменяется, и процесс повторяется снова.
• Если да, то блок добавляется в цепочку, а общедоступная книга (блокчейн) обновляется и сообщает нодам о присоединении нового блока.
• Майнеры, ответственные за данный процесс, награждаются биткоинами.
Помните номер свойства 6 хэш-функций? Удобство использования задачи?
Для каждого выхода «Y», если k выбран из распределения с высокой мин-энтропией, невозможно найти вход x таким образом, H (k | x) = Y.
Так что, когда дело доходит до майнинга биткоинов:
• К = Уникальный символ
• x = хэш блока
• Y = цель проблемы
Весь процесс абсолютно случайный, основанный на генерации случайных чисел, следующий протоколу Proof Of Work и означающий:
- Решение задач должно быть сложным.
- Однако проверка ответа должна быть простой для всех. Это делается для того, чтобы убедиться, что для решения проблемы не использовались недозволенные методы.
Вывод
Хэширование действительно является основополагающим в создании технологии блокчейн. Если кто-то хочет понять, что такое блокчейн, он должен начать с того, чтобы понять, что означает хэширование.