Машинный перевод: как все начиналось
Последние лет 10 мне регулярно говорят, что живые переводчики уже не нужны, потому что есть отличный машинный перевод, и вообще будущее за искусственным интеллектом. Да (но нет).
Машинный перевод действительно сильно продвинулся. Если еще несколько лет назад чтобы перевести письмо от китайского коллеги люди шли ко мне в бюро переводов, то сейчас они могут загнать текст в Гугл и понять, о чем речь, и нужно ли дальше привлекать переводчика.
Как развивался машинный перевод, кто вообще его придумал и когда? Сегодня немного истории.
Кстати, в Telegram-канале iTrex мы рассказываем интересное и полезное про языки, переводы и бизнес с разными странами. Присоединяйтесь!
Стереть языковые барьеры
Чтобы вы сегодня могли быстро и без особых усилий перевести текст любимой иностранной песни или пост в социальных сетях, ушли десятки и даже сотни лет кропотливого труда математиков, инженеров и лингвистов.
Эпоха великих открытий стерла морские и сухопутные географические границы, но остались языковые барьеры. В 17 веке ученые видели два пути решения проблемы:
- Создание единого языка, который было бы просто выучить любому жителю планеты.
- Создание технологии, которая позволит понимать любой язык без усилий и многих лет кропотливой учебы.
Сначала гении того времени ухватились именно за первую идею. Кстати, она пришла Рене Декарту и Готфриду Лейбницу практически одновременно. Оба математика скептически относились ко всем языкам мира, считая их нелогичными.
Было предложено создать тот самый логичный универсальный язык, который поможет понять любого чужеземца.Таким языком стал эсперанто, появившийся лишь через два века.
Его создал варшавский лингвист и окулист Лазарь Маркович Заменгоф в 1887 году после 10 лет работы. На эсперанто до сих пор публикуются книги (в России, Чехии, Италии, США, Бельгии), вещают радиостанции (В Китае, Австралии, Бразилии и Польше), а в Венгрии этот искусственный язык даже преподают в некоторых школах.
Алфавит Эсперанто. Источник: сайт TeenAge
Но пик популярности эсперанто пришелся на первую треть 20 века, когда на нем говорили многие деятели мировой революции и их сторонники. Благодаря развитию радио, к концу 20-х годов эсперанто зазвучал на 82 радиостанциях в 23 странах мира.
Первые несмелые шаги
Честь первых шагов принадлежит нашим соотечественником. Ну, или почти. Французский изобретатель Жорж Арцруни был армянином, выходцем из бывшей Российской империи. В его светлой голове родилась идея первого машинного переводчика, который, конечно, сильно отличался от современных.
Первый машинный переводчик Жоржа Арцруни. Источник: сайт CafeTran
Кстати, помимо переводчика устройство использовалось для:
- составления телефонных справочников;
- упорядочения финансовой документации;
- шифровки и дешифровки.
Это изобретение было первым устройством с памятью, на котором можно хранить информацию.
Следом за Жоржем Арцруни уже в СССР Петр Троянский представил научной общественности собственную систему машинного перевода.
Системой Троянского воспользовались и позднее — при создании клавиатуры для компьютера. Но в комплекте к устройству должен был прилагаться грамотный редактор, который приводил бы в читабельный вид полученный текст.
И 100 лет назад, и сегодня машина без человека не может сделать перевод высокого качества.
Схема системы Троянского. Источник: aclanthology
Принцип работы устройства был весьма сложен. Оператору необходимо было брать каждое слово из текста и делать его фото, а на печатной машинке вводить всю морфологическую информацию о данной лексической единице (число, падеж и др.).
По причине закрытости Советского Союза и вскоре начавшейся Второй Мировой Войны изобретение советского инженера дошло до мировой научной общественности лишь в середине 20 века.
В 40-х годах концепцию машинного перевода сформулировал американский ученый Уоррен Уивер. В основу технологии он заложил идею декодирования.
Как это работало:
- Был изобретен язык-посредник. Своему детищу он дал имя «interlingva». Это был упрощенный вариант английского языка.
- Предложение или текст сначала переводили на него.
- Затем делался перевод на требуемый язык.
То есть, interlingva был языком декодирования. Теория американского специалиста положила начало новому периоду в развитии человечества – эре машин-переводчиков.
Уоррен Уивер – автор теории декодирования. Источник: сайт wiki2
На заре новой эры
Эру открыла корпорация IBM, которая в середине 50-х провела первый в своем роде эксперимент, получивший название Джорджтаунский. Компьютерный переводчик, созданный специалистами корпорации и запущенный на компьютере 701 модели, смог справиться с 60 предложениями на русском языке.
- Оператор вводил предложения на перфокартах.
- Машинный переводчик выдавал результат, который печатался транслитом.
Для перевода были выбраны не только предложения общей тематики. Часть экспериментального текста была научной — из области органической химии.
Новый машинный переводчик выдавал перевод с невероятной для того времени скоростью (две с половиной строки в секунду).
Джорджтаунский эксперимент. Источник: сайт timetoast
Компьютерный переводчик IBM учитывал только 6 синтаксических правил, а его словарь ограничивался парой сотен слов.
Общество охватило всеобщее ликование: газеты выдавали один громкий заголовок за другим, а американские власти и частные компании готовы были выложить любые деньги на развитие новой технологии. Корпорация IBM начала упорно развивать свой машинный перевод, но последующие проекты были слишком сложными и дорогими. В итоге эксперты того времени пришли к неутешительному выводу о бесперспективности направления, а их отчет похоронил на некоторые время все дальнейшие попытки развития машинного перевода.
Финансирование всех проектов в этой сфере заморозили до 80-х, а общественность в течение этих 20 лет воспринимала машинный перевод как научную фантастику.
Тем не менее, энтузиасты остались, и одним из них был Питер Тома, глава им же созданной компании «Systran».Несмотря на скептическое отношение со стороны властей и общества, он продолжил разработку систем машинного перевода. Первые его системы работали на основе лингвистической информации и значительно ускоряли перевод текстов.
Считается, что именно вкладу Питера Тома системы машинного перевода обязаны своей востребованностью — их начали использовать практически все международные компании.
Машинный переводчик SYSTRAN. Источник: сайт caisu1.ning
А в это время…
Джорджтаунский эксперимент не оставил безучастными и советских ученых, которые занялись разработкой системы машинного перевода еще в 50-х. В то время работали две конкурирующие группы ученых под руководством математиков Дмитрия Панова и Алексея Ляпунова. Последний, кстати, был «отцом» кибернетики в Советском Союзе.
Им понадобился всего лишь год на изучение опыта своих американских коллег – и были готовы собственные наработки. Опыты проводили на отечественном компьютере БЭСМ.
Первый советский компьютерный переводчик. Источник: блог LiveJournal
Некоторое время спустя под руководством Панова был выпущен переводчик со словарным запасом более 2000 слов. Его конкурент Алексей Ляпунов «дышал в спину» и уже заканчивал свой вариант машинного переводчика.
Пришла пора подключаться к работе и языковедам. На кафедре перевода МГПИ было создано первое неформальное общество машинного перевода. В отличие от США, в нашей стране по поводу развития систем машинного перевода было больше энтузиазма – в конце 50-х была даже проведена всесоюзная конференция с участием нескольких сотен специалистов.
Конференция привлекла внимание государства, которое впоследствии поддерживало все разработки в этой сфере.
К началу 70-х в Москве началась практическая работа по созданию системы машинного перевода – ЭТАП.
Одновременно с этим в северной столице начала функционировать Научно-исследовательская лаборатория инженерной лингвистики. Ее коллектив занимался разработкой компьютерных переводчиков. А после развала СССР именно эти люди стали костяком компании PROMT во главе со Светланой Соколовой.
Современные компьютерные переводчики
Первая российская система PROMT вышла в начале 90-х. Она прекрасно справлялась, в том числе, и с переводом специализированной лексики.
Первый российский компьютерный переводчик. Источник: сайт myshared
Уже скоро PROMT начала поставлять свои решения для NASA. Кстати, сотрудничество с космической отраслью стало долгосрочным, а в 2005 году системы PROMT стали использоваться на Международной космической станции.
Во второй половине 90-х была разработана первая российская система для операционной системы Windows.
Важной вехой на пути PROMT, российского лидера в сфере информационных технологий, стал договор с французскими коллегами из Softissimo.
Эта французская компания работала с крупнейшим немецким издательством словарей Langenscheidt. Совместно с PROMT они занялись распространением компьютерных переводчиков с французского на немецкий на территории Германии.
И, наконец, к концу 90-х власти оценили усилия и заслуги компании и вручили им почетную национальную награду.
Это приятное событие совпало с выпуском Magic Gooddy, компьютерного переводчика от PROMT. Главный персонаж гусь Гудди (аналог популярного анимационного героя дятла Вудди) владел двумя языками – русским и английским. Машинный переводчик был задуман для школьников, но стал популярным и среди взрослых пользователей.
Первый российский компьютерный переводчик. Источник: сайт myshared
Команда PROMT не останавливалась на достигнутом – вскоре появился первый российский онлайн-переводчик Translate.Ru.
Машинным переводчиком тех времен стоило пользоваться с большой осторожностью во избежании нелепых ситуаций. Аналогичная ситуация и сейчас: если вам нужно перевести важный документ, стоит доверить работу с ним профессиональному бюро переводов.
Тем временем за океаном уже знакомый нам американский гигант IBM занимался разработкой систем нового поколения, которые совершеннее работали с идиомами, омонимами и многозначными словами. В 2000-х эти системы научились переводить не только отдельные слова, но и целые фразы.
Среди пользователей сегодня особо популярны два машинных переводчика – Яндекс Переводчик и Google Translate. Хотя, конечно, если прогнать фразу с помощью Google Translate через несколько языков, то исходный вариант будет сложно узнать.
Машинный перевод. Источник: сайт ppt-online
В 2016 году пришло время нейросетей – и единицей перевода стало уже не слово. Нейросети уже рассматривают предложение не как сочетание отдельных слов, а как цельную единицу текста, что уменьшает количество ошибок в переводе. Но пока заменить профессионального переводчика они не смогут. Машинным переводчикам последнего поколения не под силу многозначные лексемы или игра слов. Результат машинного перевода можно отличить от результата работы профессионального переводчика по следующим параметрам:
- ИИ пока не учитывает особенности культуры страны.
- Нейросети с трудом справляются с формулировками в переносном смысле.
- Искусственный интеллект пока не способен передать эмоции художественных произведений.
Нейросети, как и настоящие переводчики, проходят своеобразное обучение. В качестве примеров им выдают реальные тексты и их переводы. Стоит отметить, что качество работы искусственного интеллекта для разных языковых пар значительно отличается. Например, перевод с немецкого на английский нейросети делают вполне сносно, а с китайского на иврит переводить у них получается пока плохо.
Машинный перевод продолжает стремительно развиваться, ведь в мире еще много людей, не знающих иностранный язык. Им порой нужно в общих чертах понять о чем тот или иной текст. В этом на данный момент заключается главное назначение машинных переводчиков.
Границы между странами стираются, и возникает необходимость перевода контента на иностранных языках. Поэтому можно предположить, что эти технологии продолжат развиваться, а о перспективах развития я еще расскажу 🙂
КАК РАБОТАЮТ ПОПУЛЯРНЫЕ МАШИННЫЕ ПЕРЕВОДЧИКИ БЛОКЧЕЙН
Машинные переводчики блокчейн – это инновационные технологии, которые используют технику блокчейн для обеспечения безопасности и прозрачности при переводе информации. Они работают на основе смарт-контрактов, которые автоматизируют процесс перевода и исключают необходимость в посредниках.
Популярные машинные переводчики блокчейн используют нейронные сети и алгоритмы машинного обучения для обработки текстов и перевода на различные языки. Эти системы анализируют большую базу данных, включающую уже переведенные тексты, что позволяет им улучшать качество перевода по мере накопления опыта и данных.
Вся информация, связанная с переводом, хранится в блоках, которые затем связываются цепочкой и записываются в блокчейн. Это обеспечивает непрерывность и надежность перевода, а также предотвращает возможность фальсификации или изменения информации.
Популярные машинные переводчики блокчейн также обычно имеют возможность работы в режиме онлайн, что позволяет пользователям получать мгновенные переводы в реальном времени. Более того, благодаря использованию технологии блокчейн, все операции и данные о переводах остаются анонимными и недоступными для посторонних лиц.
В заключение, можно сказать, что популярные машинные переводчики блокчейн предлагают инновационное решение для обеспечения безопасности и качества перевода. Они позволяют пользователям получать мгновенные и надежные переводы, сохраняя конфиденциальность и защищая информацию от несанкционированного доступа.
010. Как работают разные инструменты автоматизации перевода и как их выбирать – Фёдор Бонч Осмоловс
6 лекция MIT — смартконтракты и DApps, блокчейн и деньги — Гари Генслер — русская озвучка — Cryptus
Что такое Блокчейн — Простое объяснение
6 СЕКРЕТОВ общения с ChatGPT [OpenAI] искусственный интеллект
Блокчейн-разработчик: это все еще актуально?
Как работает машинный перевод
Блокчейн за 5 минут. Самое простое и понятное видео
Как работает БЛОКЧЕЙН? — Научпок
Как работает нейронный машинный перевод

Машинный перевод — это задача автоматического преобразования исходного текста на одном языке в текст на другом языке (Brownlee, 2017).
Hello — 你 好 — Hola — Halo — 안녕하세요 — Hej
Знаете ли вы, на скольких языках сегодня говорят в мире? По данным Busuu, в настоящее время в мире используется примерно 6500 языков! Это указывает на то, что нелегко общаться с иностранцами без использования общеупотребительного языка, такого как английский. Кроме того, параллельно с бурным развитием технологий эти границы со временем начинают стираться. Возьмем пример Google Translate. Это один из самых важных сервисов, которые мир использует прямо сейчас для общения друг с другом. Это делает перевод между языками проще, чем использование словаря. Конечно, многоязычное общение было бы намного сложнее без него.
Рождение машинного перевода
Нейронный машинный перевод, или сокращенно NMT, — это использование моделей нейронных сетей для изучения статистической модели машинного перевода (Браунли, 2017).
Вы когда-нибудь задумывались, как работает такая технология перевода? Это восходит к 1950-м годам, когда существовала первая попытка создания такой технологии. Однако об этой идее забыли до конца 1990-х, когда машинный перевод процветал. В этот момент веб-портал AltaVista создал Babelfish — предшественника службы онлайн-перевода, такой как Google Translate. На сегодняшний день существует десятки видов машинного перевода. Одним из них является нейронный машинный перевод или NMT. NMT полагается на методы глубокого обучения и машинного обучения для повышения производительности модели при понимании контекста, выражений или даже тона языков, но, к сожалению, обучение таких моделей может занять относительно много времени.
Как сообщает Wired, модель Google Translate обучается около недели на 100 видеокартах, каждая из которых оснащена несколькими сотнями отдельных чипов.
Типы НМТ
В целом, сейчас разрабатываются два типа NMT.
Контролируемый NMT
Контролируемая передача NMT некоторых помеченных данных с исходного языка на целевой язык. Модель NMT будет обучаться на основе этих помеченных данных и, как ожидается, получит возможность перевода с исходного языка на целевой.
Неконтролируемый NMT
Этот тип NMT считается более продвинутым, поскольку он может производить перевод только с одноязычными данными, в отличие от контролируемого NMT, для которого требуется помеченная языковая пара. Такие компании, как Facebook, в настоящее время разрабатывают некоторые модели, которые можно применять для неконтролируемого NMT, такие как BERT и XLM.
Архитектура кодер-декодер
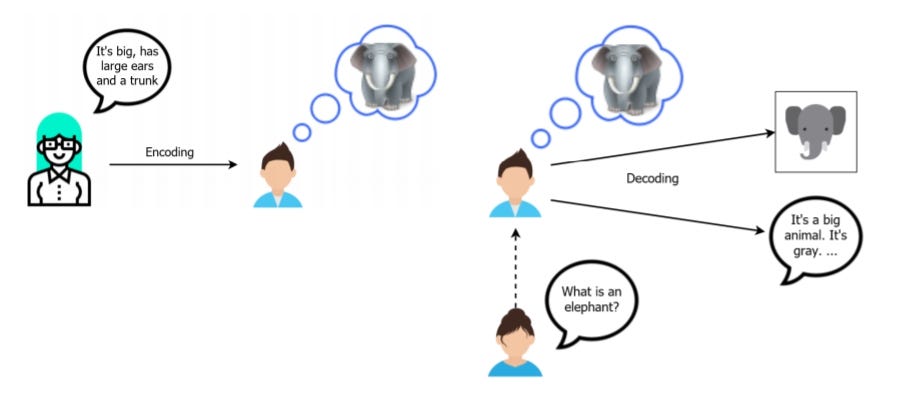
Прежде чем перейти к частям кодировщика-декодера, мы должны понять, что предложение является вводом временного ряда. Что это означает? Это означает, что в предложении на текущее слово влияет предыдущее слово.
Архитектура кодер-декодер — наиболее распространенные компоненты, которые можно найти в контролируемых моделях NMT. Он использует модель машинного обучения, которая может учиться на входных данных временного ряда (к счастью, как я объяснил, предложение ЯВЛЯЕТСЯ временным рядом). Такая модель также называется последовательной моделью. Судя по названию, кодер-декодер состоит из двух сетей: кодера и декодера. Давайте возьмем пример перевода с английского на индонезийский язык.
Я хочу хлеба — Saya mau sebuah roti
Кодировщик — кодирует исходный язык (английский) Хочу хлеба в вектор контекста. Его возможности исходят из уровней затворяемого рекуррентного блока (GRU) внутри кодировщика.
Декодер — декодирует вектор контекста в вывод последовательности ГРУ. Затем эта последовательность обрабатывается слоем Time-Distributed Dense на целевой язык (бахаса Индонезия) и создается «Saya mau sebuah roti».
Процесс NMT можно описать следующим образом:
- Кодер использует ввод на английском языке (т.е. источник).
- Кодер создает вектор контекста
- Декодер использует повторяющийся набор векторов контекста.
- Декодер выдает выходную последовательность ГРУ
- Распределенный по времени плотный слой преобразует вывод GRU на целевой язык.
Улучшение ваших моделей
Теперь, когда мы примерно знаем, как работает NMT, давайте узнаем, как его улучшить.
Принуждение учителей
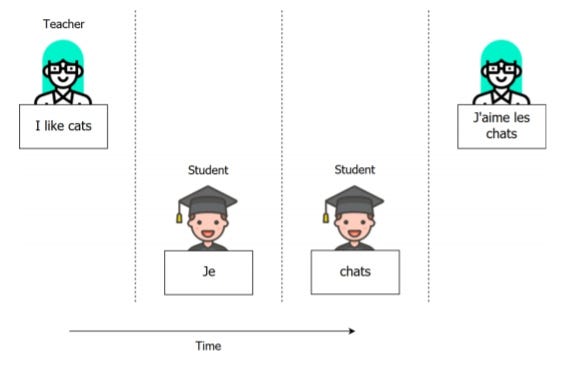
Принуждение учителей — это подход к повышению точности модели NMT путем обучения рекуррентных нейронных сетей, которые используют в качестве входных данных некоторые выходные данные предыдущего временного шага. Это похоже на концепцию обратного распространения в простой нейронной сети.
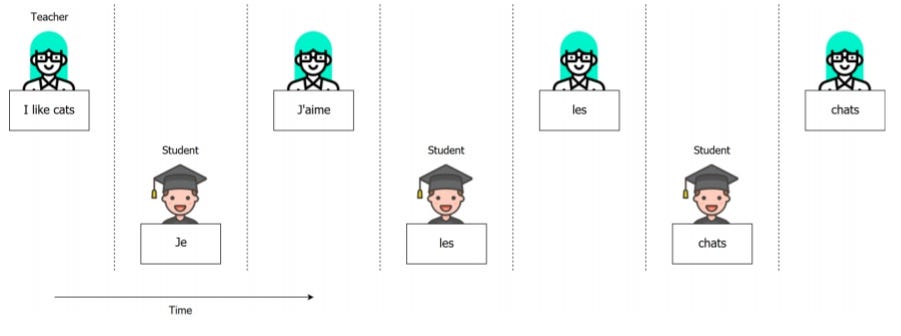
Внедрение Word
Встраивание слов — это представление и кластеризация слов, имеющих одинаковое или похожее значение. Слова классифицируются в виде вектора слов. Векторы слов фиксируют семантические отношения между словами. Одним из наиболее распространенных методов встраивания слов является Word2Vec, который может эффективно учиться на текстовом корпусе. Использование встраивания слов приведет к более быстрому достижению определенного значения точности.
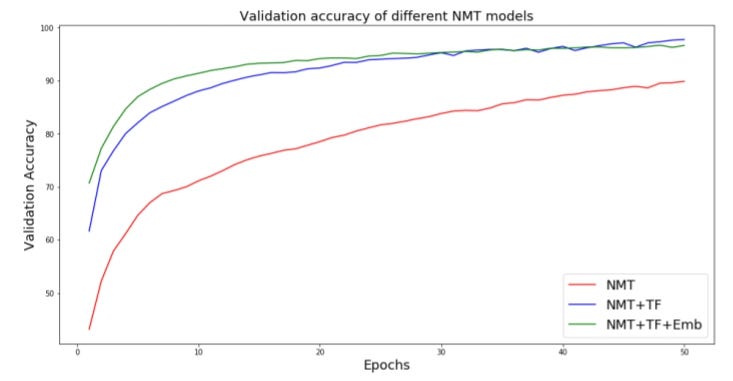
Как мы видим, принуждение учителей и встраивание слов значительно повышают точность модели по сравнению с простым NMT без какой-либо оптимизации. Встраивание слов повлияет на время, необходимое модели для достижения пороговой точности.
Оценка ваших моделей
Чтобы оценить точность модели NMT, мы часто используем так называемую двуязычную оценку дублера(BLEU). Оценка варьируется от 0,0 за полностью несоответствующий результат до 1,0 за идеальный результат.
Подход работает путем подсчета совпадающих n-грамм в переводе-кандидате с n-граммами в справочном тексте, где 1-грамм или униграмма будет каждой лексемой, а сравнением биграмм будет каждая пара слов (Brownlee, 2017).
Спасибо за чтение!
Дионисий Дэррил Хермансия — 16519126
Использованная литература:
Браунли, Джейсон. 2017. Нежное введение в расчет BLEU Score для текста в Python. Опубликовано на MachineLearningMastery.
Наука. 2019. Нейронный машинный перевод. Опубликовано на Medium.
Ганегедара, Тушан. Введение в нейронный машинный перевод. Опубликовано на DataCamp.
Что такое машинный перевод и как он работает?

Что такое машинный перевод? Это, конечно, не имеет ничего общего с наймом умного робота, но это все, что вам нужно. Говоря о машинном переводе (MT), мы говорим о таком программном обеспечении, как Google Translate, Amazon Translate и DeepL.
Хотя все инструменты машинного перевода практически выполняют одну и ту же работу, у каждого из них есть свои преимущества и недостатки. Вот все, что вам нужно знать!
Что такое машинный перевод?
Машинный перевод относится к программному обеспечению, которое использует различные формы ИИ (искусственный интеллект) для автоматического перевода контента. Что в нем замечательно, так это то, что он может работать без какого-либо вмешательства человека.
Google Translate, пожалуй, самый популярный пример программного обеспечения для машинного перевода.

Однако стоит отметить, что программное обеспечение для машинного перевода обычно не так точно. Переводчики-люди никуда не денутся, в ближайшее время.
Также стоит отметить, что МП и память переводов — это не одно и то же. Память переводов — это другой и более точный инструмент, который требует от вас наполнения его информацией. С другой стороны, МП может быть не таким точным, но он может начать перевод немедленно, автоматически и без какой-либо помощи человека.
Но оба варианта отлично подходят для упрощения и ускорения локализации при одновременном сокращении затрат на локализацию. Вам просто нужно знать, как их правильно использовать.
Как работает машинный перевод?
Итак, все, что делает MT, — это автоматически переводит контент. Довольно просто, правда? Но то, как это работает, совсем непросто.
Существует несколько типов машинного перевода, некоторые из которых более сложны и сложны, чем другие. Четыре из наиболее распространенных:
- Статистический машинный перевод
- Нейронный машинный перевод
- Машинный перевод на основе синтаксиса
- Машинный перевод на основе правил

Стоит отметить, что большинство современных машинных переводов используют комбинацию вышеперечисленных типов для достижения оптимальных результатов. И, таким образом, очень высока вероятность, что вы предпочитаете использовать гибридный машинный перевод.
Однако самые популярные MT, такие как Google Translate, Amazon Translate, DeepL и Microsoft Translate, в значительной степени полагаются на нейронные сети.
Подробнее о технических деталях ниже, для тех, кому интересно.
Статистический машинный перевод
Как следует из названия, SMT (статистический машинный перевод) полагается на перевод, сделанный человеком, чтобы выполнить свою работу. Он анализирует базу данных или базы данных, чтобы научиться переводить определенные фрагменты контента и выбирать наилучшие из возможных переводов.
Несмотря на то, что это один из самых старых и основных типов машинного перевода, многие до сих пор используют SMT в сочетании с другими типами для создания более эффективных гибридных машинных переводов.
Нейронный машинный перевод
Нейронные машины используют нейронные сети, часто в сочетании с SMT, чтобы предложить наилучшие результаты.
Под NMT, без каламбура, вы также найдете Deep NMT, который использует машинное обучение и AI (искусственный интеллект).
Поскольку нейронные сети стремятся имитировать биологический мозг, они слишком сложны, чтобы объяснять их в такой короткой статье. Итак, вы можете узнать о них немного подробнее на этой странице.
Машинный перевод на основе синтаксиса
SBMT переводит синтаксис, а не отдельные слова, и делает это путем включения этих данных в инструменты SMT (статистический машинный перевод).
Машинный перевод на основе правил
RBMT во многом полагается на контекст, такой как лингвистические и грамматические правила. И, принимая во внимание контекст, этот тип МП может переставлять слова, чтобы сформировать правильный перевод.
Человек против машины
Несмотря на все достижения в технологии машинного перевода, переводчики по-прежнему остаются лучшим выбором для перевода контента. И особенно это касается локализации.
Но почему мы не можем полностью автоматизировать перевод? У нас даже есть нейронные сети, которые стремятся имитировать настоящие вещи.

Ответ прост: инструменты машинного перевода недостаточно развиты, чтобы учитывать контекст.
Забудьте на мгновение о переводе и локализации. Даже когда мы говорим об одном языке, одно слово может иметь несколько значений, и в разных культурах могут использоваться разные высказывания, не имеющие буквального смысла.
Добавьте к этому контекст вместе с проблемами перевода и локализации, и вы сможете ясно увидеть, почему машинам так трудно конкурировать с людьми. Очевидно, только в сложных вопросах.
Как использовать машинный перевод
Машинный перевод может быть не таким точным, как переводчики-люди, но это не значит, что вам следует полностью игнорировать его. При правильном использовании MT — еще один инструмент, который может сэкономить ваше время и усилия, одновременно сократив расходы.
Похоже, что большинство людей согласны с тем, что МП — хороший выбор в качестве отправной точки. Даже если он правильно переведет только 10% всех ваших строк, это 1000 слов / предложений, с которыми вам не придется беспокоиться в проекте из 10000 слов.
Не беспокойтесь о повреждении ваших документов и кода. С современной системой управления переводами, такой как Transifex, это не должно быть проблемой.
Интеграции MT в Transifex
Transifex — это система управления переводами (TMS), которая позволяет:
- Объедините всю команду локализации в одном месте
- Переводите с помощью нашего редактора, чтобы не переключаться между документами
- Локализуйтесь быстрее и эффективнее с помощью инструментов автоматизации и интеграции
Что касается третьего пункта, в настоящее время мы предлагаем 5 инструментов машинного перевода на выбор:
- переводчик Google
- Amazon Translate
- Microsoft Translate
- DeepL
- KantanMT
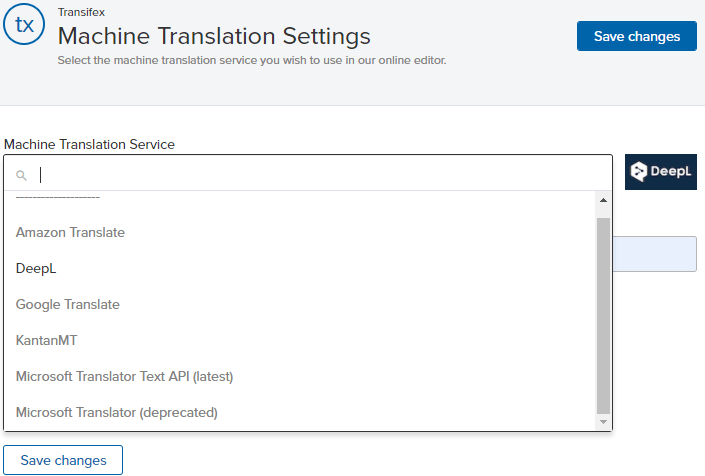
У каждого есть свои плюсы и минусы, но большинство из них довольно схожи. Например, некоторые утверждают, что DeepL более точен для языков ЕС по сравнению с конкурентами, но относятся к этому с недоверием. Мы рекомендуем вам попробовать все самостоятельно и сделать выводы.
Amazon Translate, с другой стороны, дает вам возможность связать с ней базу данных глоссария для получения более точных переводов.
Все наши интеграции с MT бесплатны для использования во всех наших планах. А если вы уже приобрели премиальный тарифный план MT, вы также можете передать его в Transifex со своим ключом API.
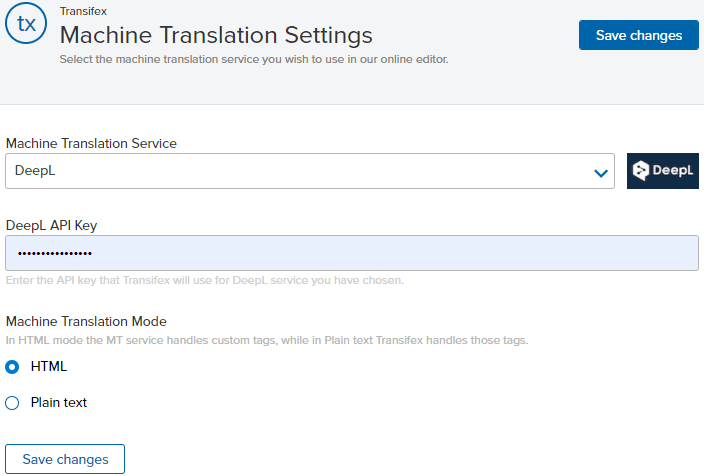
Как включить машинный перевод в Transifex
Чтобы начать использовать машинный перевод в Transifex:
- Войдите в свою учетную запись Transifex (Или создайте ее бесплатно)
- Нажмите «Transifex» в верхней правой части экрана.
- Настройки организации
- Машинный перевод
- Выберите MT из раскрывающегося меню.
- Загрузите API своей учетной записи MT
- И начни переводить
При включенном МП вы также можете активировать заполнение машинного перевода в разделе:
- (Проект на ваш выбор)
- Настройки
- Рабочий процесс
- Заполнение машинного перевода
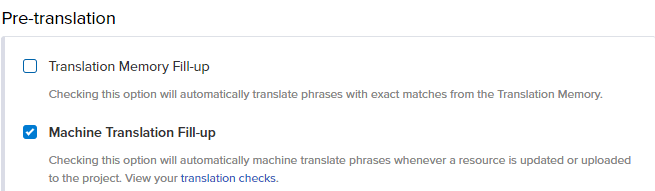
Но стоит отметить, что автоматическое пополнение TM доступно только для премиум-пользователей и выше — это то, что вы в любом случае получаете в нашей бесплатной пробной версии.
У вас также есть возможность использовать другую MT для конкретного проекта или вообще не использовать MT. Все, что вам нужно сделать, это перейти в настройки вашего проекта и выбрать «переопределить настройки машинного перевода» в правой части экрана.
Заключение
Итак, это все, что вам нужно знать о машинном переводе. Этот пост был изначально опубликован на этой странице.
- DeepL присоединяется к Transifex в качестве инструмента машинного перевода
- Что такое локализация?
- Программа памяти переводов 101