Какие видеокарты выгоднее для бизнеса — RTX 4090 или серверная RTX A5000?

В этой статье мы сравним новинку от компании Nvidia — GeForce RTX 4090 — с различными профессиональными картами от этого производителя и попытаемся ответить на вопрос «Выгодно ли использовать новую видеокарту в рабочих процессах или все-таки лучше использовать серверные видеокарты?».
Профессиональные и игровые GPU-карты имеют ряд значительных отличий, определяемых целью использования:
- Сфера применения. Серверные видеокарты применяются в ML-разработке, рендеринге и моделировании сложных объектов, научных исследованиях, кинопроизводстве и т. д. Игровые видеокарты предназначены для индивидуального использования.
- Охлаждение. Система охлаждения профессиональных карт выдувает горячий воздух из сервера или рабочей станции. Турбина охлаждения у них предназначена для постоянной работы. Игровые карты выдувают воздух вверх карты, они должны использоваться в специальных корпусах с хорошей системой вентиляции. Вентиляторы игровых карт не предназначены для длительной работы и выходят из строя при длительной постоянной эксплуатации.
- Производительность и энергоэффективность. Профессиональные GPU позволяют производить больше вычислений при меньшем энергопотреблении. Эта особенность во многом определяет высокую стоимость серверных видеокарт.
- Особенности производства. Контроль качества при изготовлении профессиональных карт строже, нежели при создании игровых.
- Разъемы. Профессиональные карты не снабжены разъемами (HDMI, DVI) для вывода видео — есть только DisplayPort.
- Дополнительный функционал. Не все серверные GPU могут быть использованы для игр.
Обзор технологии GeForce RTX 4090
Графический процессор GeForce RTX 4090 был выпущен в конце 2022 года и стал продолжением линейки десктопных ускорителей от компании NVIDIA, что вызвало большой интерес у игроков по всему миру.
Ключевыми особенностями карты являются:
- Как и во всей линейке GeForce RTX 40, используются новые графические процессоры AD10x (в 4090 — AD102) на основе архитектуры Ada Lovelace и с применением технологического процесса 4N (TSMC).
- Повышена производительность операций трассировки лучей и машинного вычисления на тензорных ядрах.
- Технологический процесс 4N позволяет повысить энергоэффективность на несколько процентов.
- Размер карты (304 на 137 мм, 3 слота) осложняет ее монтаж как в настольных ПК, так и в серверах.
- Игровая система охлаждения, что зачастую делает невозможным использование 4090 в GPU-серверах.
- По сравнению с 3090, в AD102 на 70% больше CUDA-ядер.
- Технология NVIDIA DLSS 3 использует алгоритмы анализа векторов движения и OFA.
- Платформа NVIDIA Reflex с низкой задержкой позволяет повысить качество игры профессиональных геймеров.
- Кодировщик NVEnc 8-го поколения с поддержкой кодирования AV1.
- Приложение NVIDIA Broadcast.
- NVIDIA Studio.
Технические характеристики видеокарт NVIDIA RTX A4000, NVIDIA RTX A5000, NVIDIA RTX 3090 и NVIDIA RTX 4090
Количество транзисторов (млрд.)
Тактовая частота (ГГц)
Тактовая частота с ускорением (ГГц)
Memory frequency (МГц)
Пропускная способность памяти (Гб/с)
Cache memory (Мб)
Количество текстурных модулей
Максимальная мощность (Вт)
Вычислительная производительность FP16 (half) (терафлопс)
Вычислительная производительность FP32 (float) (терафлопс)
Вычислительная производительность FP64 (double)
Теоретическая максимальная скорость закраски (гигапикселей/с)
Теоретическая скорость выборки текстур (гигатекселей/с)
Двухплатная низкопрофильная конфигурация (мосты на 2 и 3 слота)
Поддержка ПО Virtual GPU (vGPU)
NVIDIA Virtual PC (vPC) и Virtual Applications (vApps), NVIDIA RTX vWS, NVIDIA Virtual Compute Server
Новая архитектура, пропускная способность памяти и количество тензорных ядер, технология DLSS 3 и другие характеристики GeForce RTX 4090 определяют широкий спектр применения графического процессора — не только гейминг, но и работа с искусственным интеллектом, сложными вычислениями.
Тестирование HOSTKEY
Описание тестовой среды:
- Процессор AMD Ryzen 9 5900 X 12-Core Processor (3.80 GHz)
- 32 GB DDR4-3200 ECC DDR4 SDRAM 1600 МГц
- Microsoft Windows 10 Professional 64-разрядная
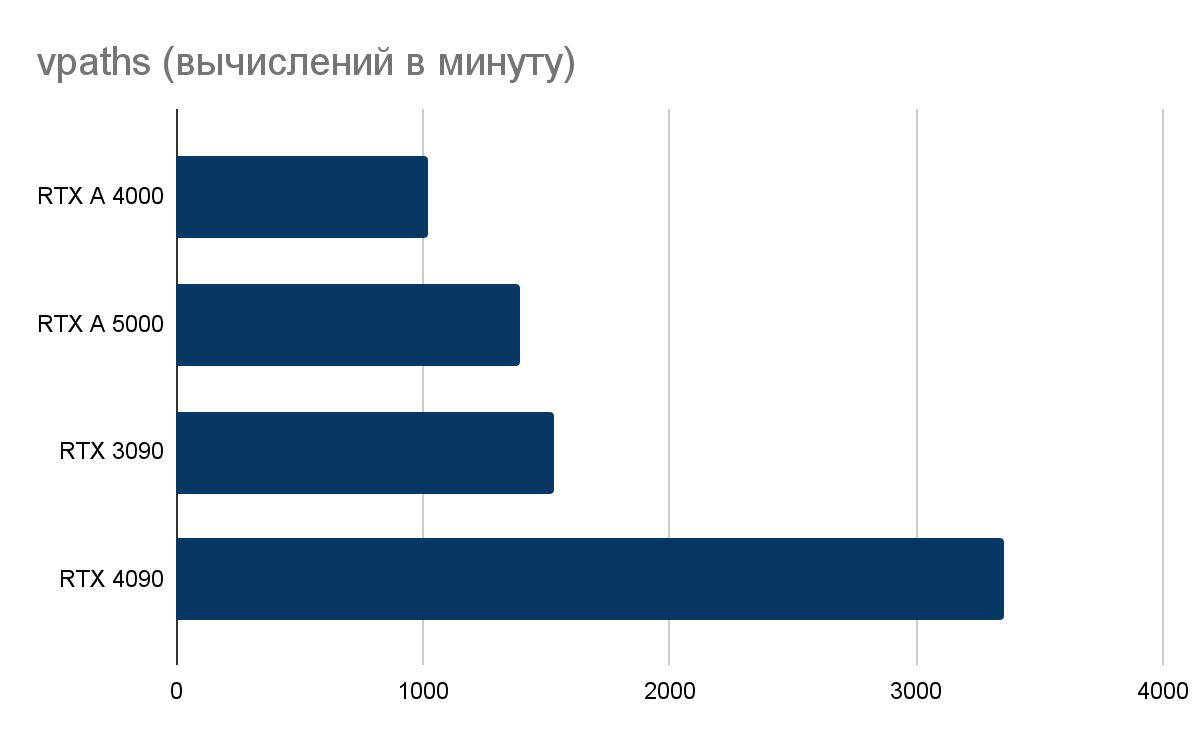
Tест V-Ray GPU CUDA
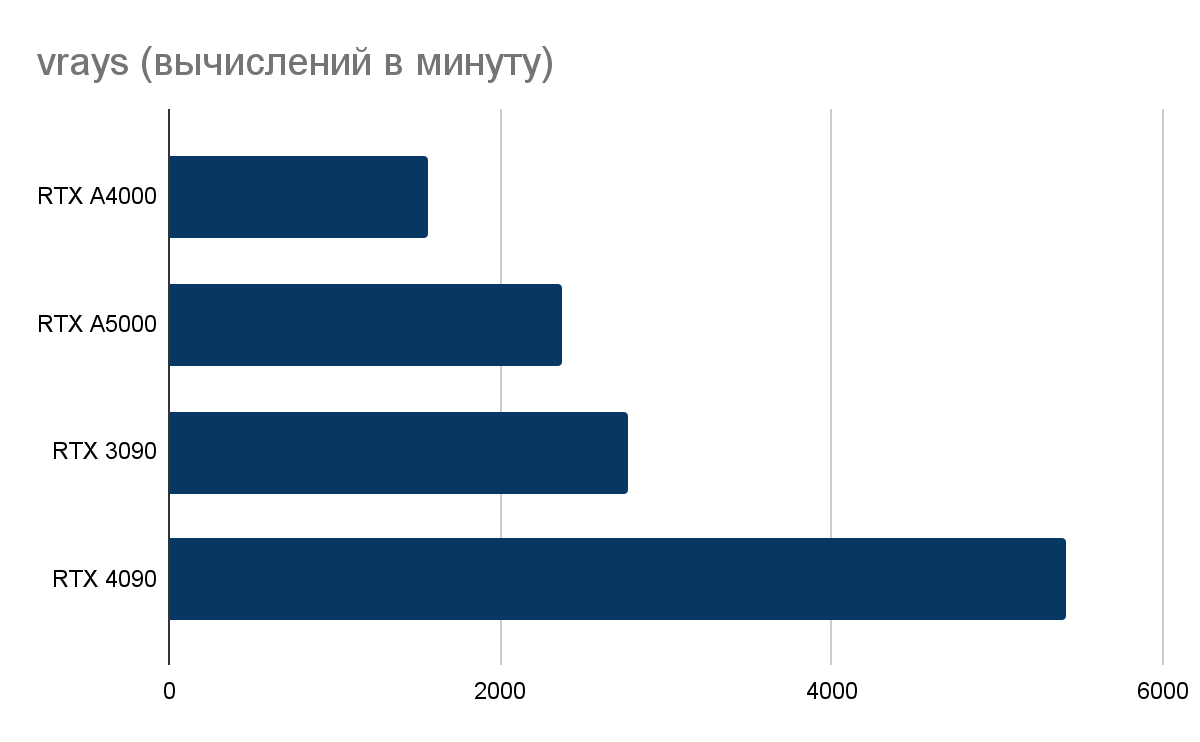
Tест V-Ray GPU RTX
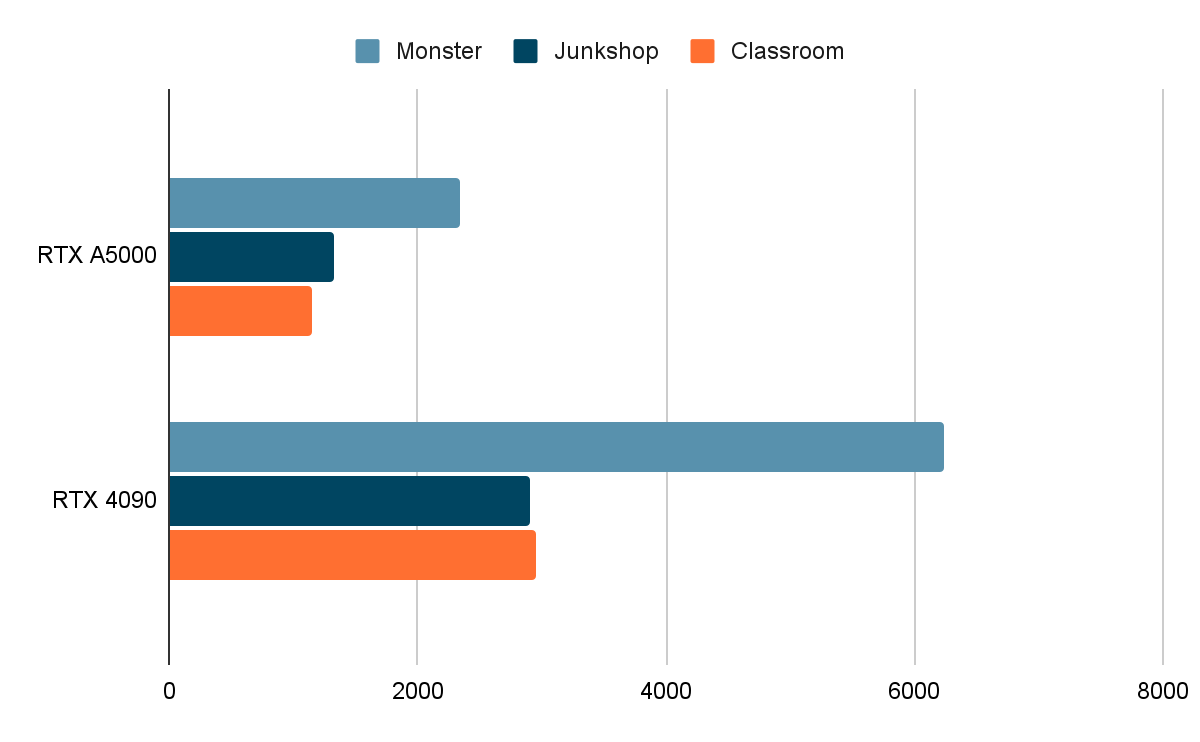
Blender Benchmark
В этом тесте и в LuxMark мы сравним только карты RTX A5000 и RTX 4090, поскольку они наиболее интересны в контексте этой статьи.
LuxMark
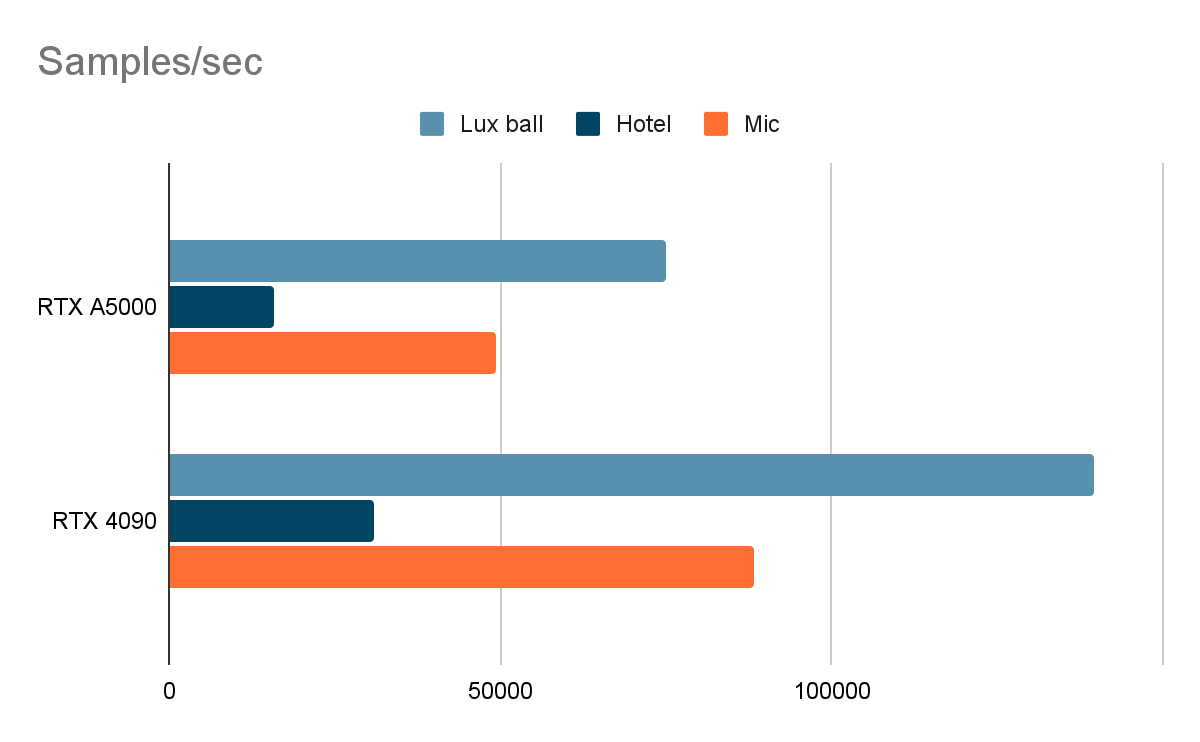
Мы измерили относительную производительность GPU при рендеринге. Показатели GeForce RTX 4090 в тестах выглядят впечатляюще и превосходят практически вдвое не только результаты RTX 3090, но и профессиональные GPU. Тест V-Ray GPU RTX демонстрирует работу GPU с трассировкой лучей — показатели RTX 4090 также в два раза превосходят результаты RTX 3090.
«Собаки против кошек»
Для сравнения производительности GPU для нейросетей мы используем набор данных «Собаки против кошек» — тест анализирует содержимое фотографии и различает, изображена на фото кошка или собака. Все необходимые исходные данные находятся здесь. Мы запускали этот тест на разных GPU и в различных облачных сервисах, получили следующие результаты:
Полный цикл обучения (мин.)

Полный цикл обучения тестовой нейросети занял от 31 до 60 минут. Результат GeForce RTX 4090 составил 31 минуту и превзошел показатели всех остальных GPU. Наиболее заметна разница в результатах карт RTX 3090 и RTX 4090 — новое поколение ГПУ от NVIDIA справилось с расчетами почти вдвое быстрее предыдущего.
Тесты показали, что ближайшим конкурентом карты 4090 является A5000. Осталось сравнить эти карты по соотношению цена-качество. Во всех проведенных тестах новая карта от Nvidia показала результат, превышающий показатель RTX A5000 примерно вдвое. В то же время стоимость RTX 4090 значительно ниже: 138 тысяч рублей (минимальная цена) против 216 тысяч. Казалось бы, выбор очевиден — но есть нюансы. GPU A5000 потребляет значительно меньше энергии и может быть выгодным решением для задач с постоянной высокой нагрузкой на GPU на длинной дистанции. RTX A5000 поддерживает технологию NVLink, что полезно при обучении нейронных сетей. GPU A5000 не имеют ограничений на использование NVENC/NVDEC при задачах параллельного транскодирования видео. При покупке специализированной лицензии профессиональные GPU класса A5000 могут быть виртуализированны и доступны в сервере как несколько виртуальных GPU меньшей мощности. Еще одна проблема — запрет Nvidia на использование драйверов для своих игровых карт в дата-центрах и в удаленном режиме вне офиса.
Хотя на промофото NVidia много 4090 с большими вентиляторами и формате 3 юнита, в реальности эту конфигурацию практически невозможно купить. На складах есть только игровые карты большого размера на 4 юнита и повышенной высоты с выдувом вверх и вниз карты. Такие карты не могут быть использованы в серверах и большинстве рабочих станцией.

Заключение
Переход на новую архитектуру Ada Lovelace позволил значительно увеличить производительность GeForce RTX 4090. Улучшенные тензорные ядра и ядра RT значительно повышают качество и расширяют возможности трассировки лучей в реальном времени. Объем памяти в 24 Гб позволяет обрабатывать большие массивы данных.
GeForce RTX 4090 в первую очередь предназначена для гейминга и прекрасно подходит для решения различных типов вычислительных задач: ИИ, анализ данных, машинное обучение. Новая архитектура значительно превосходит предыдущее поколение графических процессоров от NVIDIA. Важное ограничением в профессиональном использовании этой видеокарты — высокое энергопотребление и отсутствие возможности объединить несколько карт при помощи Nvlink.
Альтернативой приобретению видеокарты является аренда сервера с GPU. Наши расчеты показывают, что месячная аренда карт GeForce RTX 4090 и RTX A5000 сопоставима по цене. Соответственно, при необходимости выполнения профессиональных задач аренда карты GeForce RTX 4090 может быть выгодна за счет ее высокой производительности.
Арендуйте выделенные и виртуальные GPU серверы с профессиональными графическими картами NVIDIA RTX A5000 / A4000 в надежных дата-центрах класса TIER III в Москве и Нидерландах. Принимаем оплату за услуги HOSTKEY в Нидерландах в рублях на счет российской компании. Оплата с помощью банковских карт, в том числе и картой МИР, банковского перевода и электронных денег.
Топ-10 видеокарт для машинного обучения

Как правильно выбрать видеокарту и максимально эффективно обрабатывать большие объемы данных и выполнять параллельные вычисления.
Введение
Один из главных факторов успешной работы с машинным обучением — это правильный выбор видеокарты, которая позволит максимально быстро и эффективно обрабатывать большие объемы данных и выполнять параллельные вычисления. Большинство задач машинного обучения, особенно тренировка глубоких нейронных сетей, требует интенсивной обработки матриц и тензоров. Отметим, что в последнее время все большую популярность набирают TPU, FPGA и специализированные AI-чипы.
Какие характеристики видеокарты важны для проведения машинного обучения?
При выборе видеокарты для машинного обучения есть несколько ключевых характеристик, на которые следует обратить внимание:
- Вычислительная мощность: количество ядер/процессоров определяет параллельные вычислительные возможности видеокарты.
- Объем памяти GPU: большой объем позволяет эффективно работать с большими данными и сложными моделями.
- Поддержка специализированных библиотек: аппаратная поддержка таких библиотек, как CUDA или ROCm, ускоряет процесс обучения моделей.
- Поддержка высокой производительности: быстрая память и широкая шина памяти обеспечивают высокую производительность при обучении моделей.
- Совместимость с фреймворками машинного обучения: необходимо убедиться, что выбранная видеокарта полностью совместима с используемыми фреймворками и поддерживаемыми инструментами разработчика.
Сегодня в области производства графических процессоров для машинного обучения лидирует компания NVIDIA. Оптимизированные драйверы и поддержка CUDA и cuDNN позволяет GPU от NVIDIA значительно ускорить вычисления.
Графические процессоры AMD хороши для игр, они менее распространены в области машинного обучения из-за ограниченной поддержки программного обеспечения и необходимости частых обновлений.
Сравнительная таблица видеокарт для машинного обучения
Объем памяти (Гб)
Тактовая частота, ГГц
Peak FP32 TFLOPS
Peak FP64 TFLOPS
Ядра CUDA
Тензорные ядра
Ядра RT
Пропускная способность памяти (Гб/с)
Разрядность шины видеопамяти (бит)
Максимальная мощность (Вт)
NVLink
Цена (USD)
Цена
(руб)
Tesla V100
Только в модели для серверов c NVLink
Quadro RTX 8000
2 Quadro RTX 8000 GPUs
A100
A 6000 Ada
RTX A 5000
RTX 4090
RTX 4080
RTX 4070
RTX 3090 TI
RTX 3080 TI
NVIDIA Tesla V100

GPU с тензорными ядрами, разработанный для работы с технологиями искусственного интеллекта, высокопроизводительными вычислениями (HPC) и задачами машинного обучения. Основанный на архитектуре NVIDIA Volta, Tesla V100 обеспечивает производительность в 125 триллионов операций с плавающей запятой в секунду (TFLOPS).
Плюсы:
- Высокая производительность: видеокарта Tesla V100 оснащена архитектурой Volta с 5120 ядрами CUDA, что обеспечивает очень высокую производительность при выполнении задач машинного обучения. Она способна обрабатывать большое количество данных и выполнять сложные вычисления с высокой скоростью.
- Большой объем памяти: 16 гигабайт памяти HBM2 позволяют эффективно обрабатывать большие объемы данных при обучении моделей, что особенно полезно при работе с крупными датасетами. Разрядность шины видеопамяти (4096 бит) позволяет обеспечить высокую скорость передачи данных между процессором и видеопамятью, улучшая производительность обучения и вывода моделей машинного обучения.
- Технологии глубокого обучения: видеокарта поддерживает различные технологии глубокого обучения, в том числе Tensor Cores, которые ускоряют вычисления с использованием операций с плавающей точкой. Это позволяет значительно снизить время обучения моделей и повысить их производительность.
- Гибкость и масштабируемость: Tesla V100 может использоваться как в настольных компьютерах, так и в серверных системах. Она поддерживает различные фреймворки машинного обучения, такие как TensorFlow, PyTorch, Caffe и другие, что обеспечивает гибкость в выборе инструментов для разработки и обучения моделей.
Минусы:
- Высокая стоимость: NVIDIA Tesla V100 является профессиональным решением и имеет соответствующую цену. Ее стоимость (14 447 долларов) может быть довольно высокой для частных лиц или небольших команд машинного обучения.
- Потребление энергии и охлаждение: видеокарта Tesla V100 потребляет значительное количество энергии и генерирует значительное количество тепла. Это может потребовать соответствующих мер по охлаждению в системе, а также привести к повышенным энергозатратам.
- Требования к инфраструктуре: для полноценного использования Tesla V100 необходима подходящая инфраструктура, в том числе мощный процессор и достаточное количество оперативной памяти.
NVIDIA A100

Обеспечивает производительность и гибкость, необходимые для машинного обучения. Работая на базе новейшей архитектуры NVIDIA Ampere, A100 обеспечивает до пятикратного повышения производительности обучения по сравнению с графическими процессорами предыдущего поколения. NVIDIA A100 поддерживает множество приложений и фреймворков для искусственного интеллекта.
Плюсы:
- Высокая производительность: большое количество ядер CUDA — 4608.
- Большой объем памяти: у видеокарты NVIDIA A100 — 40 ГБ памяти HBM2, что позволяет эффективно работать с большими объемами данных при обучении моделей глубокого обучения.
- Поддержка технологии NVLink: эта технология позволяет объединять несколько видеокарт NVIDIA A100 в одну систему для выполнения параллельных вычислений, что повышает производительность и ускоряет обучение моделей.
Минусы:
- Высокая стоимость: NVIDIA A100 является одной из самых мощных и производительных видеокарт на рынке, поэтому имеет высокую стоимость — 10 000 долларов.
- Потребление энергии: использование видеокарты NVIDIA A100 требует значительного количества энергии. Это может привести к увеличению затрат на электроэнергию и требовать дополнительных мер предосторожности при развертывании в больших центрах обработки данных.
- Совместимость с программным обеспечением: видеокарта NVIDIA A100 требует соответствующего программного обеспечения и драйверов для оптимальной работы. Некоторые программы и фреймворки машинного обучения могут не полностью поддерживать эту конкретную модель видеокарты.
NVIDIA Quadro RTX 8000

Одна карта Quadro RTX 8000 способна визуализировать сложные профессиональные модели с реалистичными тенями, отражениями и преломлениями, предоставляя пользователям быстрый доступ к информации. При использовании технологии NVLink ее память можно расширить до 96 ГБ.
Плюсы:
- Высокая производительность: Quadro RTX 8000 обладает мощным графическим процессором и 5120 ядрами CUDA.
- Поддержка технологии Ray Tracing: аппаратное ускорение трассировки лучей позволяет создавать фотореалистичные изображения и эффекты освещения. Это может быть полезным при работе с визуализацией данных или компьютерной графикой в рамках задач машинного обучения.
- Большой объем памяти: 48 ГБ графической памяти GDDR6 обеспечивают достаточное пространство для хранения больших моделей машинного обучения и данных.
- Поддержка библиотек и фреймворков: Quadro RTX 8000 полностью совместима с популярными библиотеками и фреймворками машинного обучения, такими как TensorFlow, PyTorch, CUDA, cuDNN и другими.
Минусы:
- Высокая стоимость: Quadro RTX 8000 является профессиональным графическим ускорителе, что делает его достаточно дорогим в сравнении с другими видеокартами. Актуальная стоимость данной видеокарты составляет 8200 долларов.
RTX A6000 Ada

Эта видеокарта предлагает идеальное сочетание производительности, цены и низкого энергопотребления, что делает его оптимальным вариантом для профессионалов. Благодаря передовой архитектуре CUDA и 48 ГБ памяти GDDR6, A6000 обеспечивает высокую производительность. Обучение на RTX A6000 может выполняться с максимальными размерами партий.
Плюсы:
- Высокая производительность: архитектура Ada Lovelace, ядра RT третьего поколения, тензорные ядра четвертого поколения и ядра CUDA нового поколения с 48 ГБ видеопамяти.
- Большой объем памяти: видеокарты NVIDIA RTX A6000 Ada оснащена 48 ГБ памяти, что позволяет эффективно работать с большими объемами данных при обучении моделей.
- Низкое энергопотребление.
Минусы:
- Высокая стоимость: RTX A6000 Ada стоит около 6800 долларов.
NVIDIA RTX A5000

RTX A5000 основана на архитектуре NVIDIA Ampere и оснащена 24 Гб памяти, что обеспечивает быстрый доступ к данным и ускоряет обучение моделей машинного обучения. Благодаря 8192 ядрам CUDA и 256 тензорным ядрам карта обладает огромной вычислительной мощностью, позволяющей выполнять сложные операции.
Плюсы:
- Высокая производительность: большое количество ядер CUDA и высокая пропускная способность памяти позволяют обрабатывать большие объемы данных с высокой скоростью.
- Поддержка аппаратного ускорения AI: видеокарта RTX A5000 предлагает аппаратное ускорение для операций и алгоритмов, связанных с искусственным интеллектом.
- Большой объем памяти: 24 ГБ GDDR6 видеопамяти позволяют работать с большими наборами данных и сложными моделями машинного обучения.
- Поддержка фреймворков машинного обучения: видеокарта RTX A5000 хорошо интегрируется с популярными фреймворками машинного обучения, такими как TensorFlow и PyTorch. Она имеет оптимизированные драйверы и библиотеки, которые позволяют эффективно использовать ее возможности для разработки и обучения моделей.
Минусы:
- Потребление энергии и охлаждение: видеокарты такого класса обычно потребляют значительное количество энергии и генерируют большое количество тепла во время работы. Для эффективного использования RTX A5000 необходимо обеспечить правильное охлаждение и иметь достаточную мощность блока питания.
NVIDIA RTX 4090

Эта видеокарта обладает высокой производительностью и функциями, которые делают ее идеальной для приведения в действие новейшего поколения нейронных сетей.
Плюсы:
- Выдающаяся производительность: NVIDIA RTX 4090 способна эффективно обрабатывать сложные вычисления и большие объемы данных, ускоряя процесс обучения моделей машинного обучения.
Минусы:
- Охлаждение — одна из основных проблем, с которой пользователи могут столкнуться при использовании NVIDIA RTX 4090. Из-за мощного тепловыделения карта может нагреваться до критического уровня и автоматически отключаться для предотвращения повреждений. Это особенно актуально в многокартных конфигурациях.
- Ограничения в конфигурации: конструкция графического процессора ограничивает возможность установки большего количества карт NVIDIA RTX 4090 в рабочую станцию.
NVIDIA RTX 4080

Представляет собой мощную и эффективную графическую карту, обеспечивающую высокую производительность в области искусственного интеллекта. За счет высокой производительности и цены данная карта является хорошим выбором для разработчиков, желающих получить максимальную отдачу от своих систем. RTX 4080 имеет трехслотовый дизайн, что позволяет установить до двух графических процессоров в рабочем компьютере.
Плюсы:
- Высокая производительность: карта оснащена 9728 ядрами NVIDIA CUDA, что обеспечивает высокую производительность вычислений в задачах машинного обучения. Также наличие тензорных ядер и поддержка трассировки лучей способствует более эффективной обработке данных.
- Стоимость карты — 1199 долларов, что позволяет получить производительное решение для машинного обучения частным лицам и небольшим командам.
Минусы:
- Ограничение SLI: карта не поддерживает NVIDIA NVLink с функцией SLI, что означает, что нельзя объединять несколько таких карт в режиме SLI для увеличения производительности.
NVIDIA RTX 4070

Эта видеокарта создана на основе архитектуры NVIDIA Ada Lovelace и оснащена 12 Гб памяти, что обеспечивает быстрый доступ к данным и ускоряет обучение моделей машинного обучения. Благодаря 7680 ядрам CUDA и 184 тензорным ядрам карта обладает хорошей вычислительной мощностью, позволяющей выполнять сложные операции. Отличный выбор для всех, кто только начинает изучать машинное обучение.
Плюсы:
- Высокая производительность: 12 Гб памяти и 7680 ядер CUDA позволяют работать с большими объемами данных.
- Низкое энергопотребление: 200 Вт.
- Низкая стоимость — 599 долларов.
Минусы:
- Ограниченная память: 12 ГБ памяти ограничивают возможности обработки больших объемов данных в некоторых приложениях машинного обучения.
- Нет поддержки NVIDIA NVLink и SLI: карты не поддерживают технологию NVIDIA NVLink для объединения нескольких карт в системе параллельной обработки. Это может ограничить масштабируемость и производительность в многокартных конфигурациях.
NVIDIA GeForce RTX 3090 TI

Это игровой GPU, который также может быть использован для глубокого обучения. RTX 3090 TI позволяет достичь пиковой производительности одинарной точности (FP32) в размере 13 терафлопсов, а также оснащен 24 ГБ видеопамяти и 10 752 ядрами CUDA.
Плюсы:
- Высокая производительность: архитектура Ampere и 10 752 ядра CUDA позволяют решать сложные задачи машинного обучения.
- Ускорение аппаратного обучения: RTX 3090 TI поддерживает технологию Tensor Cores, которая обеспечивает аппаратное ускорение операций нейронной сети. Это может значительно ускорить процесс обучения моделей глубокого обучения.
- Большой объем памяти: с 24 Гб памяти GDDR6X RTX 3090 TI может обрабатывать большие объемы данных в памяти без необходимости частых операций чтения и записи на диск. Это особенно полезно при работе с крупными наборами данных.
Минусы:
- Потребление энергии: видеокарта имеет высокое энергопотребление (450 Вт), что требует мощного блока питания. Это может повлечь дополнительные затраты и ограничить возможности использования видеокарты в некоторых системах, особенно в случае использования нескольких карт в параллельных вычислениях.
- Компатибельность и поддержка: возможны проблемы совместимости и несовместимости с некоторыми программными платформами и библиотеками машинного обучения. В некоторых случаях могут потребоваться специальные настройки или обновления программного обеспечения для полной поддержки видеокарты.
NVIDIA GeForce RTX 3080 TI

RTX 3080 TI — отличная карта среднего уровня, которая обеспечивает высокую производительность и является хорошим выбором для тех, кто не хочет тратить большие суммы на профессиональные видеокарты.
Плюсы:
- Высокая производительность: RTX 3080 оснащена архитектурой Ampere с 8704 ядрами CUDA и 12 ГБ памяти GDDR6X, что обеспечивает высокую вычислительную мощность для выполнения сложных задач машинного обучения.
- Ускорение аппаратного обучения: видеокарта поддерживает Tensor Cores, что позволяет получить значительное ускорение при выполнении операций нейронной сети. Это способствует более быстрому обучению моделей глубокого обучения.
- Относительно доступная цена — 1499 долларов.
- Ray Tracing и DLSS: RTX 3080 поддерживает аппаратное ускорение трассировки лучей (Ray Tracing) и Deep Learning Super Sampling (DLSS). Эти технологии могут быть полезными при визуализации результатов моделей и обеспечивают более высокое качество графики.
Минусы:
- Ограниченный объем памяти — 12 ГБ, может ограничить возможности работы с большими объемами данных или сложными моделями, требующими больше памяти.
Если вас интересует машинное обучение, вам понадобится хорошая видеокарта (GPU), чтобы приступить к работе. Но с таким разнообразием типов и моделей на рынке может быть сложно определить, какая из них подходит именно вам.
Арендуйте выделенные и виртуальные GPU серверы с профессиональными графическими картами NVIDIA RTX A5000 / A4000 в надежных дата-центрах класса TIER III в Москве и Нидерландах. Принимаем оплату за услуги HOSTKEY в Нидерландах в рублях на счет российской компании. Оплата с помощью банковских карт, в том числе и картой МИР, банковского перевода и электронных денег.
- Блог компании HOSTKEY
- Data Mining
- Машинное обучение
- Искусственный интеллект
- Видеокарты
NVIDIA RTX A5000: технические характеристики и тесты
NVIDIA начала продажи RTX A5000 12 апреля 2021. Это топовая десктопная видеокарта на архитектуре Ampere и техпроцессе 8 нм, в первую очередь рассчитанная на дизайнеров. На ней установлено 24 Гб памяти GDDR6 на частоте 16 Гб/с, и вкупе с 384-битным интерфейсом это создает пропускную способность 768.0 Гб/с.
С точки зрения совместимости это двухслотовая карта, подключаемая по интерфейсу PCIe 4.0 x16. Длина референсной версии – 267 мм. Для подключения требуется дополнительный 1x 8-pin кабель питания, а потребляемая мощность – 230 Вт.
Она обеспечивает хорошую производительность в тестах и играх на уровне 59.27% от лидера, которым является NVIDIA GeForce RTX 4090.
GeForce RTX 4090
Общая информация
Сведения о типе (для десктопов или ноутбуков) и архитектуре RTX A5000, а также о времени начала продаж и стоимости на тот момент.
| Место в рейтинге производительности | 23 | |
| Место по популярности | не в топ-100 | |
| Соотношение цена-качество | 0.94 | |
| Архитектура | Ampere (2020−2022) | |
| Графический процессор | GA102 | |
| Тип | Для рабочих станций | |
| Дата выхода | 12 апреля 2021 (2 года назад) | |
| Цена сейчас | 3327$ | из 168889 (A100 PCIe 80 GB) |
Соотношение цена-качество
Отношение производительности к цене. Чем выше, тем лучше.
Характеристики
Общие параметры RTX A5000: количество шейдеров, частота видеоядра, техпроцесс, скорость текстурирования и вычислений. Они косвенным образом говорят о производительности RTX A5000, но для точной оценки необходимо рассматривать результаты бенчмарков и игровых тестов.
| Количество потоковых процессоров | 8192 | из 20480 (Data Center GPU Max NEXT) |
| Частота в режиме Boost | 1695 МГц | из 3599 (Radeon RX 7990 XTX) |
| Количество транзисторов | 28,300 млн | из 14400 (GeForce GTX 1070 SLI (мобильная)) |
| Технологический процесс | 8 нм | из 4 (GeForce RTX 4080) |
| Энергопотребление (TDP) | 230 Вт | из 2400 (Data Center GPU Max Subsystem) |
| Скорость текстурирования | 433.9 | из 969.9 (H100 SXM5 96 GB) |
Совместимость и размеры
Параметры, отвечающие за совместимость RTX A5000 с остальными компонентами компьютера. Пригодятся например при выборе конфигурации будущего компьютера или для апгрейда существующего. Для десктопных видеокарт это интерфейс и шина подключения (совместимость с материнской платой), физические размеры видеокарты (совместимость с материнской платой и корпусом), дополнительные разъемы питания (совместимость с блоком питания).
| Интерфейс | PCIe 4.0 x16 |
| Длина | 267 мм |
| Толщина | 2 слота |
| Дополнительные разъемы питания | 1x 8-pin |
Оперативная память
Параметры установленной на RTX A5000 памяти — тип, объем, шина, частота и пропускная способность. Для встроенных в процессор видеокарт, не имеющих собственной памяти, используется разделяемая — часть оперативной памяти.
| Тип памяти | GDDR6 | |
| Максимальный объём памяти | 24 Гб | из 192 (Radeon Instinct MI300X) |
| Ширина шины памяти | 384 бит | из 19000 (GeForce RTX 3080 12 GB) |
| Частота памяти | 16 Гб/с | из 22400 (GeForce RTX 4080) |
| Пропускная способность памяти | 768.0 Гб/с | из 3276 (Aldebaran) |
Видеовыходы
Перечисляются имеющиеся на RTX A5000 видеоразъемы. Как правило, этот раздел актуален только для десктопных референсных видеокарт, так как для ноутбучных наличие тех или иных видеовыходов зависит от модели ноутбука.
| Видеоразъемы | 4x DisplayPort |
Поддержка API
Перечислены поддерживаемые RTX A5000 API, включая их версии.
| DirectX | 12 Ultimate (12_2) |
| Шейдерная модель | 6.6 |
| OpenGL | 4.6 |
| OpenCL | 3.0 |
| Vulkan | 1.2 |
| CUDA | 8.6 |
NVIDIA RTX A5000 Mobile: технические характеристики и тесты
NVIDIA начала продажи RTX A5000 Mobile 12 апреля 2021. Это ноутбучная видеокарта на архитектуре Ampere и техпроцессе 8 нм, в первую очередь рассчитанная на геймеров. На ней установлено 16 Гб памяти GDDR6 на частоте 14 ГГц, и вкупе с 256-битным интерфейсом это создает пропускную способность 448.0 Гб/с.
С точки зрения совместимости это карта, подключаемая по интерфейсу PCIe 4.0 x16. Потребляемая мощность – 165 Вт (80 — 150 Вт TGP).
Она обеспечивает хорошую производительность в тестах и играх на уровне 39.54% от лидера, которым является NVIDIA GeForce RTX 4090.
GeForce RTX 4090
Общая информация
Сведения о типе (для десктопов или ноутбуков) и архитектуре RTX A5000 Mobile, а также о времени начала продаж и стоимости на тот момент.
| Место в рейтинге производительности | 93 |
| Место по популярности | не в топ-100 |
| Архитектура | Ampere (2020−2022) |
| Графический процессор | GA104 |
| Тип | Для ноутбуков |
| Дата выхода | 12 апреля 2021 (2 года назад) |
Характеристики
Общие параметры RTX A5000 Mobile: количество шейдеров, частота видеоядра, техпроцесс, скорость текстурирования и вычислений. Они косвенным образом говорят о производительности RTX A5000 Mobile, но для точной оценки необходимо рассматривать результаты бенчмарков и игровых тестов.
| Количество потоковых процессоров | 6144 | из 20480 (Data Center GPU Max NEXT) |
| Частота ядра | 1215 МГц | из 2610 (Radeon RX 6500 XT) |
| Частота в режиме Boost | 1770 МГц | из 3599 (Radeon RX 7990 XTX) |
| Количество транзисторов | 17,400 млн | из 14400 (GeForce GTX 1070 SLI (мобильная)) |
| Технологический процесс | 8 нм | из 4 (GeForce RTX 4080) |
| Энергопотребление (TDP) | 165 Вт (80 — 150 Вт TGP) | из 2400 (Data Center GPU Max Subsystem) |
| Скорость текстурирования | 302.4 | из 969.9 (H100 SXM5 96 GB) |
Совместимость и размеры
Параметры, отвечающие за совместимость RTX A5000 Mobile с остальными компонентами компьютера. Пригодятся например при выборе конфигурации будущего компьютера или для апгрейда существующего. Для ноутбучных видеокарт это предполагаемый размер ноутбука, шина и разъем подключения, если видеокарта подключается через разъем, а не распаивается на материнской плате.
| Размер ноутбука | Большой |
| Интерфейс | PCIe 4.0 x16 |
| Дополнительные разъемы питания | нет |
Оперативная память
Параметры установленной на RTX A5000 Mobile памяти — тип, объем, шина, частота и пропускная способность. Для встроенных в процессор видеокарт, не имеющих собственной памяти, используется разделяемая — часть оперативной памяти.
| Тип памяти | GDDR6 | |
| Максимальный объём памяти | 16 Гб | из 192 (Radeon Instinct MI300X) |
| Ширина шины памяти | 256 бит | из 19000 (GeForce RTX 3080 12 GB) |
| Частота памяти | 14000 МГц | из 22400 (GeForce RTX 4080) |
| Пропускная способность памяти | 448.0 Гб/с | из 3276 (Aldebaran) |
| Разделяемая память | — |
Видеовыходы
Перечисляются имеющиеся на RTX A5000 Mobile видеоразъемы. Как правило, этот раздел актуален только для десктопных референсных видеокарт, так как для ноутбучных наличие тех или иных видеовыходов зависит от модели ноутбука.
| Видеоразъемы | No outputs |
Поддержка API
Перечислены поддерживаемые RTX A5000 Mobile API, включая их версии.
| DirectX | 12 Ultimate (12_2) |
| Шейдерная модель | 6.6 |
| OpenGL | 4.6 |
| OpenCL | 3.0 |
| Vulkan | 1.2 |
| CUDA | 8.6 |